

Market Guide 2025: The Rise of Security Data Pipelines & How SIEMs Must Evolve
A practical roadmap for CISOs modernizing the SOC data layer: How security data pipelines are redefining SIEM economics and laying the groundwork for the future Security Operations Center (SOC)


Readers
Over the past year, one of the most hyped and most-talked about sectors in cybersecurity has been the SOC, specifically the push towards the “AI‑SOC”, built on the premise of LLMs triaging security alerts and automating human analysts. Rightly so, and I’ve written my thoughts on that here. But something bigger has been happening.
In December 2024, in one of my most viral posts on the SOC, I pointed out that SACR research indicated a quieter, yet far more decisive shift in the SOC: the data layer. This is the layer I pointed to as being the most important, because without clean, well‑routed telemetry, even the smartest AI is starved of context. This report explains the reasoning behind that shift.
The evidence didn't take too long to follow. In February, a leading pipeline vendor, Cribl, reported crossing $200 million in ARR only six years after launch. It also became one of the fastest companies ever to surpass $100M ARR in October 2023, reaching that milestone behind only Wiz, HashiCorp, and Snowflake. This is a milestone many cybersecurity firms never reach. What does this mean?
It’s clear: CISOs are voting with their budget. Data‑first architecture delivers immediate ROI. This Market Guide explains why the SOC data layer now drives cost, analyst experience and increasingly detection quality. I’m also excited to introduce our inaugural Security Data Pipeline Platform (SDPP) vendor ranking—a soft launch of our new scoring methodology that will guide our research reports this year.
Inside you’ll find:
A clear definition of the SDPP market and its place between SIEM, XDR, and data lakes
A breakdown of how the SOC works, including key sources and destinations
Planning assumptions and CISO‑level metrics for budgeting pipeline initiatives
A benchmark of the critical capabilities every modern security pipeline must provide and how the SIEM is evolving
Vendor assessments that weigh execution strength against vision as pipelines evolve from basic log reduction to autonomous, AI‑oriented data fabrics
Use this report to evaluate platforms, refine your SOC roadmap, and separate hype from infrastructure that truly moves the needle.
Security Data Pipeline Platforms (SDPP)
How Vendors Are Ranked: Our Methodology Explained (See the full report, or visit the vendor’s capabilities section). Alternatively, visit this spreadsheet for full ranking criterion and analysis.
**
Disclosure:
This report is made free and open to everyone. That’s only possible thanks to the collaborative support and contribution of leading industry vendors who share our commitment to advancing security research. These vendors accepted my independent analysis and criteria, which I used to develop the ranking for this market. Each of them was selected based on having some of the most relevant indicators for inclusion in this evaluation.
**We recommend opening this research in a web browser due to its length **
Introduction: Key Report Conclusions
Focus of the Report: This report focuses on the rapid rise of the Security Data Pipeline Platforms (SDPP).
Market Vendors & Partnerships: The SDPP market is heading toward convergence. While more than 30 companies offer some form of pipeline capability, SACR specifically narrowed its analysis to 11 vendors; 9 within the pure-play pipeline category and 2 with adjacent SIEM + Security Data Pipeline capabilities. These vendors represent some of the most significant participants in this space, ranging from established players to early-stage companies with differentiated approaches.
The Ranking of Vendors: The ranking process we developed combines aggregate Crunchbase scoring with a deeper evaluation of technical capabilities beyond core pipeline capabilities.
Legacy SIEMs Are Breaking Under Pressure:
It’s no longer a secret that the SIEM is undergoing a big transformation. SIEMs as we know them are struggling to keep up with the ever-expanding growth of logs and security telemetry data. Traditional SIEMs, which charge based on ingestion volume, are becoming economically unsustainable. As data from cloud, endpoint, identity, and network tools grows exponentially, SOCs face difficult trade-offs: either reduce logging (and risk visibility gaps), shorten data retention (and hinder investigations), or absorb massive costs. These limitations expose a core problem that legacy SIEMs were not built for today’s distributed, high-volume environments.
The Future of the SIEM into 2025/2026: Based on our research, we believe that legacy on-prem SIEMs will continue to have a place over the next five years because of how embedded they’ve become in the largest of enterprises. However, we’re seeing the SIEM evolve from monolithic to modular, driven by cost pressure. Instead of being a monolithic system that stores and analyzes all data, modern SIEMs are evolving into modular platforms that separate storage from analytics. This “query layer” model allows data to live in cheaper storage (like Snowflake or Azure Blob) while being queried on demand. SIEMs are also embracing open formats like OCSF and JSON, enabling easier integration and reducing vendor lock-in. Their core focus is narrowing toward real-time alerting, with long-term search and retention delegated to adjacent systems.
Security Data Pipeline Platforms (SDPPs) are emerging as a Critical Preprocessing Layer
To address these SIEM limitations, modern SOCs are deploying dedicated Security Data Pipeline Platforms (SDPPs) as an intelligent preprocessing layer. These platforms clean, enrich, normalize, filter, and route telemetry before it reaches downstream systems such as SIEMs, XDRs, or security data lakes. By removing noise and standardizing formats early, SDPPs help reduce storage costs, accelerate investigations, and enable analysts to focus on high-value alerts. In effect, they serve as a security refinery, converting crude telemetry into structured, context-rich signals.
5 Core Reasons Why Security Data Pipeline Management Will Keep Growing
This is going to be one of the biggest markets over the next few years. The growth of the pipeline market is being fueled by multiple pressures. First, the sheer volume of telemetry is rising due to cloud adoption, IoT, tool sprawl, and new categories of AI apps and AI security solutions. Second, SIEM licensing models are financially unsustainable for large-scale data ingestion. Third, regulatory demands from GDPR to the SEC’s new cyber disclosure rules require high-quality, auditable log data. Fourth and adjacent is the compliance requirement around reporting. Auditors and risk officers need time data to regulatory reports, and these solutions help solve this challenge. Lastly, security tools often produce logs in different formats, increasing the complexity of correlation and detection unless the data is transformed in a pipeline first.
Future Trends of Security Data Pipelines
The future of the pipeline market is being affected by agentic AI use cases and MCP protocols. Once static pipelines are becoming increasingly intelligent and detection aware. AI and large language models are poised to reshape the telemetry pipeline. Logs, with their rich detail, are particularly valuable for training or querying LLMs.
AI/LLM disrupting detection engineering: More importantly, we're seeing pipelines evolve into agentic systems. These are AI-driven bots that can automatically act like AI data engineers by generating parsing rules and enriching data in real time. In the near future, pipelines may not only preprocess data but also run detection logic and respond to threats without relying on a downstream SIEM. We expect pipelines to begin acting as real-time threat sensors, capable of executing detection rules (like Sigma) on or before data reaches the SIEM. Over time, they may serve as orchestrators for automated response. Additionally, pipelines are being embedded into broader architectures as part of a security data fabric that unifies ingestion, storage, and analysis.
Vendor Evaluation Framework: To evaluate vendors in the SDPP space, we propose a dual lens: technical depth and business momentum. Technically, vendors should be assessed on core capabilities like ingestion speed, normalization quality, integration breadth, and support for open standards (e.g., OCSF). On the business side, key indicators include funding raised, customer base, ecosystem partnerships, and presence in the enterprise security stack. We placed an emphasis on vendors that have had product maturity in a capability for a long period of time. We believe that tools offering both flexibility and future-readiness, particularly in AI augmentation and threat or streaming analytics, are positioned to lead.
The State of the SOC in 2025
The modern Security Operations Center (SOC) architecture can be broadly and simplistically categorized into three foundational layers, each responsible for a critical stage in security operations:
The data layer is the entry point into the SOC. It encompasses data ingestion and routing from diverse security sources such as Endpoint Detection & Response
Storage, Detection, and Analytics Layer: This middle layer manages the storage, analysis, and detection capabilities essential for threat identification. It leverages different classes of systems across SIEMs and data platforms
AI-Augmented Response & Decision Layer: This last layer leverages triage, automation and enrichment to accelerate threat response and decision-making.

The Data Layer: Why Security Data Pipeline Platform (SDPP) is a Big Market Opportunity
The effectiveness of any Security Operations Center (SOC) fundamentally depends on the quality, relevance, and timeliness of data it processes. Without a robust data layer, everything else built upon it—analytics, detection, response automation—crumbles under unreliable or incomplete insights. Here are our key conclusions if you have only have a few minutes to read the report:
Growing data volume from security tools & it’s complexity: The sheer volume, variety, and velocity of data are constantly increasing, especially with the rise of cloud workloads, IoT/OT devices, and new cybersecurity solutions. This creates a massive need for a robust SDPP to manage this data effectively. The report illustrates this clearly in the security context, with organizations struggling to handle the “vast amount of security data generated from distributed networks, endpoints, cloud environments, and third-party services”.
Legacy SIEMs are expensive and security data pipeline enhance faster migrations: Traditional SIEMs often use pricing models based on the volume of data ingested. Since many are still on-prem, their SIEM costs skyrocket as organizations try to keep up with data growth, making it harder to maintain comprehensive security visibility. These are the tradeoffs most teams face:
Reduce logging: Log less data, which creates blind spots and increases security risk.
Filter aggressively: Filter out potentially valuable data to save on ingest, risking missed threats.
Limit retention: Shorten data retention periods, which hinders long-term threat hunting and forensic analysis.
Data quality & compliance reporting:
In 2023, the SEC adopted new rules requiring public companies to disclose material cybersecurity incidents and their risk management practices. These disclosures must be made shortly after determining the incident is material.
Many compliance mandates require organizations to maintain accurate, detailed records of security events, logs, and activities. This includes who accessed what data, when, and from where. Poor data quality (e.g., incomplete logs, inaccurate timestamps) can undermine the integrity of these records, making it difficult to prove compliance during audits or investigations
Compliance with security regulations and standards (like GDPR, HIPAA, PCI DSS, NIST) hinges on an organization's ability to properly collect, manage, and protect sensitive data.
When a security incident occurs, organizations must be able to respond quickly and effectively. High-quality data facilitates incident investigation, allowing security teams to identify the scope of the breach, assess the damage, and take corrective actions
Compliance also requires organizations to prove they have full audit trails, showing that accountability and visibility exist.
Complexity of security engineering is rising with the rise of different data formats: Most organizations rely on more than 40–50 security tools. Over 90% of them send alerts to SIEMs for correlation and threat detection. This includes SIEMs, EDRs, NDRs, cloud platforms, identity management systems, vulnerability scanners, and more. Each tool generates logs in different formats, with its own semantics, schemas, and storage needs. A big part of this complexity stems from modern infrastructure: containers, microservices, and elastic cloud environments. Resources spin up and down. IP addresses constantly change. Network topologies shift. This makes it extremely difficult to track activity, baseline behavior, or detect anomalies. Traditional security tools aren’t built for this kind of ephemeral environment. As a result, it’s become a nightmare for security engineers to normalize data, correlate events, build comprehensive dashboards or automate workflows across fragmented toolchains.
Shift to real-time data processing: In today’s threat landscape, speed matters. Attacks unfold in minutes, and delays in detection or response can lead to real damage. But many traditional security tools rely on batch processing, which introduces latency and hinders real-time visibility. There's a growing demand for real-time or streaming SDPP to enable immediate insights and actions. This is particularly critical in security, where responding to threats in real-time can minimize damage. This report highlights "real-time stream processing" as one of the core value drivers behind modern security telemetry pipelines.
The Rapid Growth of Data in Cybersecurity
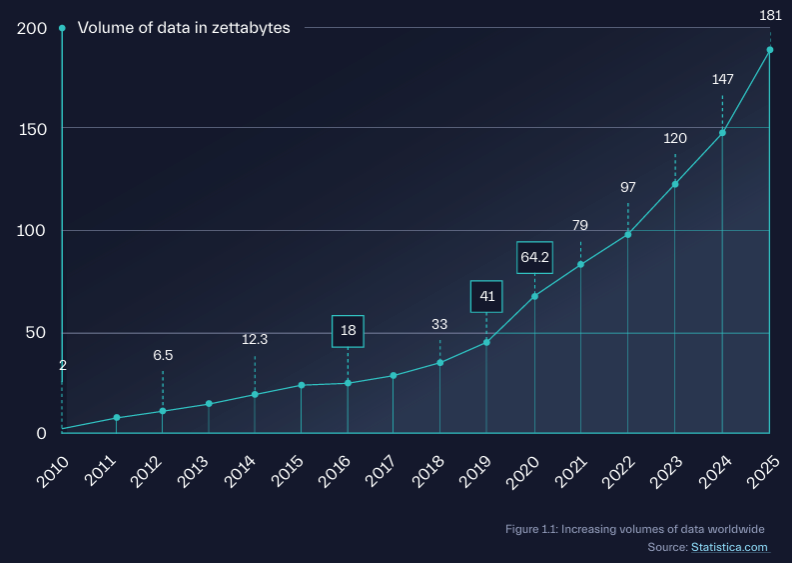
It’s no longer a surprise; the rise of data across the enterprise, and especially within security operations, has skyrocketed in recent years.
The modern security landscape is drowning in data. Every endpoint, server, application, and network device now generates a torrent of logs and alerts.
This explosion is being further accelerated by cloud-native architectures, microservices, containers, and SaaS platforms, each introducing new layers of telemetry. As organizations expand into hybrid and multi-cloud setups, security teams are ingesting billions of events daily from hundreds of disparate sources.
What once fit neatly into a centralized SIEM is now overwhelming traditional tools. The volume, variety, and velocity of security telemetry have exceeded the assumptions legacy systems were built on. From high-cardinality EDR logs to API traces, the SOC is no longer just consuming logs; it’s processing structured, semi-structured, and unstructured telemetry across the full MELT spectrum.
Defining Data and Its Context in Data Security
Last year, I wrote extensively about data in the context of data security use cases. This time, we’re looking at data as it relates to security operations.

This report drills down into the security telemetry category as it relates to all the security logs and events data that organizations collect from various security tools, including EDR systems, firewalls, cloud security logs, IAM systems, application logs, threat intelligence feeds, Windows Event Logs, and other sources. These are key dataset that need to be ingested into a SIEM.
Security Telemetry Data Types (MELT)

Security Data Pipeline Platforms (SDPP)
Security Data Pipeline Platforms (SDPP) are purpose-built systems that ingest, normalize, enrich, filter, and route large volumes of security telemetry across hybrid and cloud environments. These platforms sit between data sources (like EDRs, cloud logs, and firewalls) and destinations (like SIEMs, data lakes, XDRs, and analytics tools). Their goal is to optimize the flow and quality of telemetry data to reduce operational complexity and cost while increasing the speed and accuracy of detection and response.
Confusion & Misconceptions
Security Data Pipeline Management vs. Business ETL: It’s important to clarify that security data pipelines (like Cribl) and business ETL pipelines (like DBT Labs, Fivetran) serve fundamentally different purposes.
Data Processing Focus: Security data pipelines prioritize real-time threat detection and noise reduction from security telemetry, while business ETL focuses on transforming structured data for analytics and reporting. Time sensitivity is critical in security data pipelines, which requires immediate stream processing for threat detection, whereas business ETL typically operates in batches for business intelligence.
Security Data Fabric vs. Security Data Pipeline Platforms (SDPP): Security data fabric refers to an architectural approach that enables secure, unified, and governed access to distributed security-relevant data, regardless of where it resides. It encompasses broader datasets such as security logs, business data, compliance records, asset metadata, and identity systems. In contrast, SDPPs focus specifically on product capabilities aimed at managing and processing security telemetry i.e. logs, events, metrics, traces, and threat data.
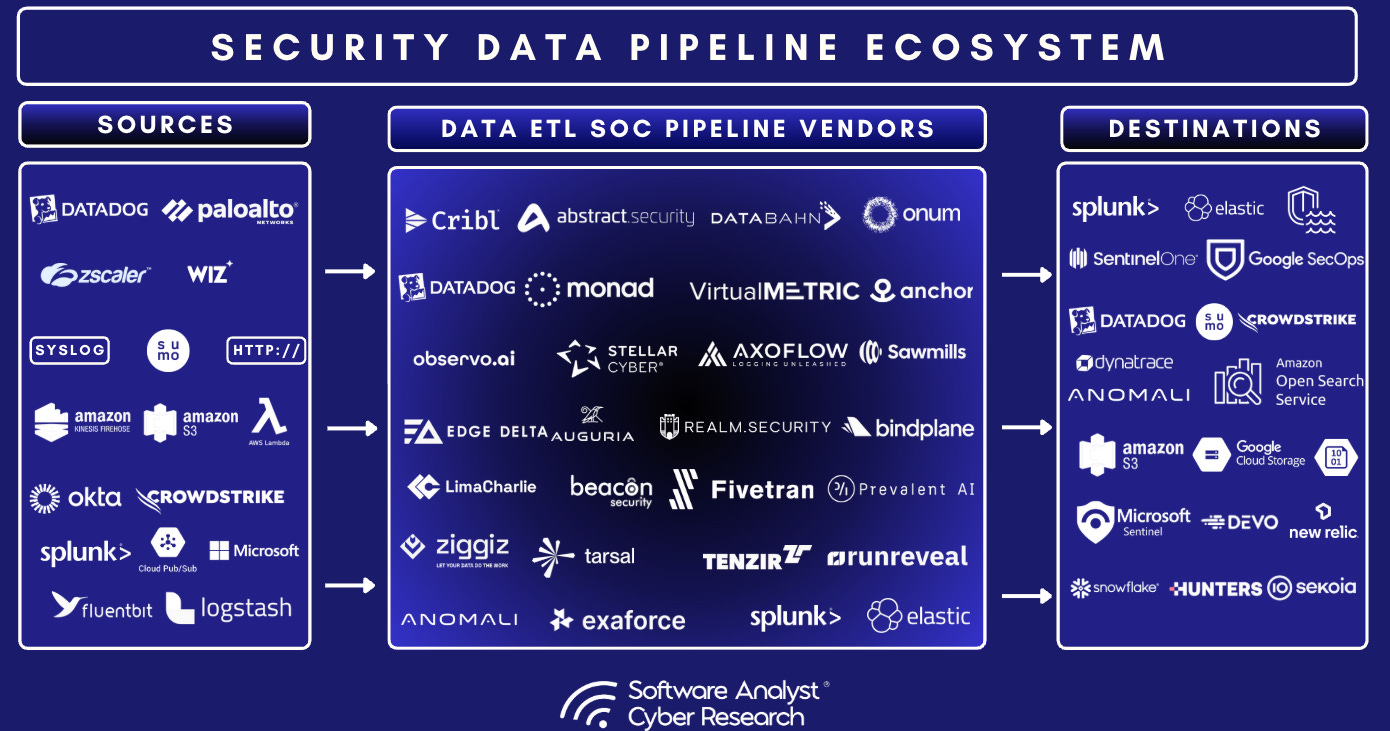
How SOC DPP Works
In the world of SOC pipelines, there are sources and destinations;

Sources (Security Tools)
A data pipeline is the connective tissue that carries raw telemetry from where it’s born to where it creates value. In security operations, this is where everything starts. Sources are the first mile—the systems, sensors, and applications that generate raw telemetry such as logs, metrics, events, and traces. Getting sources right is critical: capture only what is useful, tag it with rich context (timestamps, asset IDs, schemas), and reduce noise as early as possible to control cost and keep downstream tooling performant. Some examples includes:
Endpoint & User‑Device Telemetry: CrowdStrike Falcon EDR alerts, Microsoft Defender for Endpoint incidents, SentinelOne agent telemetry, kernel audited events
Network & Perimeter Telemetry: Palo Alto NGFW traffic logs, Cisco ASA NetFlow records, Zeek IDS logs, Cloudflare Gateway DNS logs
Cloud & Infrastructure Audit Logs: AWS CloudTrail events, Azure Activity Logs, Google Cloud Audit Logs, AWS VPC Flow Logs
Identity & Access Management Events: Okta sign‑in logs, Azure AD conditional‑access events, on‑prem Active Directory security logs, Duo MFA authentication records, CyberArk PAM session logs
Application & SaaS Logs: Windows Event Logs, NGINX access logs, AWS API Gateway request logs, Kubernetes Ingress controller logs, Salesforce Shield events, Office 365 Management Activity (SharePoint/Teams)
Operating‑System & Host Logs: Windows Event ID 4625 (failed logon), Sysmon process‑creation logs, Linux syslog auth messages, macOS Unified Log entries, systemd‑journald service logs
File & Data‑Access Telemetry: AWS S3 access logs, SharePoint file‑access logs, OneDrive audit logs, NetApp ONTAP file‑server logs, PostgreSQL pgAudit trails
External & Threat‑Intelligence Feeds: Includes AlienVault OTX pulse feeds; CISA “Known Exploited Vulnerabilities” (KEV) catalogue, VirusTotal file / URL reputation stream and Recorded Future Intelligence Cloud API.
Fun Fact from the Applied Security Data Strategy Book:
One of the highest volume data sources includes endpoint security and malware sandbox data. Threat intelligence is another major contributor. They observed that many organizations face a key dilemma: "Managing terabytes of distributed security data results in a compromise between speed of retrieval and storage costs," with most organizations particularly struggling with endpoint security.

Destinations (Storage/Analysis)
At the other end of the pipeline sit the destination platforms that transform telemetry into insight or action. This is the storage layer, or increasingly the analysis layer, where data becomes actionable.
These range from real-time engines like SIEMs and SOARs, where milliseconds matter, to lower-cost data lakes or lakehouses for long-term analytics, compliance, and machine learning. Choosing the right destination mix hinges on latency, retention, and access pattern requirements: hot, indexable storage for immediate investigation; colder, scalable storage for retrospective hunts. Destinations turn well-prepared data into security outcomes.
SIEMs: For real-time monitoring, correlation, and alerting
XDR platforms: For extended detection and response across security layers
Security data lakes: For long-term storage, threat hunting, and forensic analysis
SOAR / Automation systems: For automated incident response workflows
AI/ML platforms: For advanced threat detection and behavioral analysis
The report highlights how security telemetry pipelines can feed various security tools and architectures, improving their effectiveness.
The Process
Data ingestion is a critical process that involves gathering raw data from various sources and transporting it to a destination where it can be analyzed, processed, and stored. Think of it like refining oil: raw data must be collected before it becomes the fuel needed to power valuable insights.
Security telemetry is collected from a wide range of sources and loaded into analytics tools. Pipelines transform it through parsing, normalization, enrichment, and redaction, then load it into destinations like SIEMs, data lakes, SOAR platforms, or AI engines. The result is better structured, lower volume, higher context data that enables faster and more accurate threat detection.
How Data Is Extracted from Source to Destinations
Data can be collected from identified sources by teams using two main methods:
Push Methods
Syslog
HTTP listeners
Message brokers
Pull Methods
Agents
Agentless
APIs / Listeners
Once data is received, the "transform" stage is where security focused data pipelines shines in a SOC. This stage acts as a critical preprocessing layer that makes raw telemetry workable and cost-effective for security analytics. Instead of dumping unfiltered logs directly into the SIEM, modern security teams deploy pipeline tools to filter, parse, enrich, redact, and transform the data in transit. As a result, by the time the data reaches the SIEM or security data lake, it is cleaner, normalized, and significantly reduced in volume. In essence, the pipeline functions as a security data refinery. It takes in crude log data from various sources and outputs refined, context-rich events that are ready for detection engines.

How Security Data Pipeline Transformation Happens
There are six core processes that define the key capabilities and functionalities of a Security Data Pipeline Platform (SDPP):
Data Filtering & Reduction: The first and most basic functionality is filtering and reducing noise by removing redundant or low-value data, such as duplicate logs or benign events, and aggregating related events. Excessive, unfiltered data can strain systems, slowing query responses and causing potential downtime. The pipeline drops or routes away data that is not needed for security monitoring.
For instance, it might filter out debug logs, routine successful authentication events, or other low-value data that consume unnecessary SIEM storage. This log reduction often uses rules or machine learning to identify redundant events and reduce volume by 80% or more without losing relevant signals. The immediate benefit is smaller log sizes, lower SIEM ingestion costs, and reduced analyst clutter.
Parsing & Structuring: After filtering, the next step is parsing raw logs, which are typically just text strings. Pipelines parse these into structured fields. For example, an unstructured firewall syslog line is converted into structured fields such as source IP, destination IP, port, and action. Similarly, a Windows Event XML can be parsed into structured fields. This transformation from free text to structured events is crucial for SIEM correlation rules, which rely on specific field values. Pipelines may use regex, custom parsers, or built-in knowledge of common log formats. Modern pipelines or SIEM tools often include libraries of pre-built parsers for popular log sources, reducing the need for writing parsing code manually.
Normalization & Transformation into Data Formats: Another critical step involves pipelines normalizing data and transforming events to conform to common schemas or naming conventions. Popular schemas include Splunk’s Common Information Model (CIM), the Open Cybersecurity Schema Framework (OCSF), or Elastic Common Schema (ECS), all aiming to standardize cybersecurity data. Different products describe events differently (e.g., an “allow” action might be
action=permitin one device andoutcome=allowin another). Pipelines can rename and map such fields into standardized schemas (like converting both to a fieldoutcome=allowedfor consistency).Business analytics and generic data tools often struggle with format standardization, while security focused pipelines have built-in support for frameworks like OCSF. By normalizing in the pipeline, the SIEM’s correlation and search become much more effective, allowing analysts to query unified fields across multiple sources. The pipeline essentially models and classifies data for analysis. Standardizing logs and events from different sources into a common format makes them comparable and searchable, addressing the challenge of disparate data formats that hinder analysis. The end result is schema transformation, shaping data specifically for security tools like SIEMs, XDRs, or security data lakes, optimizing their performance and analytical capabilities.
Enrichment: Enrichment is an area gaining momentum across the industry. The goal of enrichment is to add context such as threat intelligence, geolocation, asset information, and user behavior analytics to log data. This transforms raw logs into meaningful security events that are crucial for alert prioritization and investigation.
Pipelines can augment each log with additional information that isn’t present in the raw data. Common enrichments include: GeoIP lookup (adding geographic location info for IP addresses), WHOIS or domain reputation lookup for domains, pulling in host asset information (e.g., tagging an IP with the hostname or owner from a CMDB), user context (adding department or role info for a user from an HR database), and threat intelligence tagging (marking if an IP or URL in the log appears on threat intel blacklists). For example, if a firewall log shows a connection from IP X, the pipeline could append “IP X is located in China and is on a known blacklist.” This turns raw logs into context-rich alerts; analysts get more actionable data, and automated correlation can use these fields (e.g., flag any connection from blacklisted countries). Enrichment at the pipeline stage ensures that when the data reaches the SIEM, it already includes relevant intelligence. This significantly speeds up investigations since analysts no longer need to manually look up information. It also improves prioritization. For example, the pipeline could tag certain events as high priority if they involve high-value assets or known bad IPs.
Redaction & Masking capabilities support data privacy requirements: Sometimes logs contain sensitive information (PII like user passwords, personal data, or confidential info) that should not be freely stored or viewed. Pipelines can redact or mask fields to address privacy and compliance concerns. For example, they might hash an email address or remove a credit card number from logs before they land in a data lake. This function is crucial in regulated industries. It allows broad data collection without exposing sensitive data to unnecessary risk. Redaction policies can be applied so that only authorized destinations (or users) can ever see the original values. In essence, the pipeline enforces data security and privacy by design, scrubbing logs as needed.
Routing & Tiering into storage locations: The final stage of transformation involves routing and tiering. After filtering, structuring, normalizing, enriching, and redacting, pipelines can route logs to different destinations based on content, priority, or compliance requirements. Not all data needs to remain in an expensive SIEM environment indefinitely. For example, a pipeline might route high-value security events (e.g., an IDS alert or critical server logs) to the SIEM for real-time alerting, but send low-risk audit logs to a cheaper security data lake (such as AWS S3 or Snowflake) for archival. Some data may be duplicated across storage types. One copy might be retained in the SIEM with short-term retention, while another is archived in a data lake for long-term compliance. This type of storage tiering is a significant cost optimization strategy. For instance, an organization could retain 30 days of parsed alerts in the SIEM and one year of raw logs in a data lake, all managed by the pipeline.
The pipeline acts as a traffic controller, ensuring that each stream of telemetry reaches the right system—whether that be a SIEM, XDR, data lake, or automation platform. By decoupling data routing from any single vendor tool, pipelines offer flexibility. If an organization decides to change SIEM providers or introduce a new analytics platform, it can do so simply by updating pipeline routing rules, without reconfiguring every source.
How Security Data Storage like the SIEM Is Evolving in 2025
The SIEM in association with SDPP
The SIEM remains the epicentre of the SOC. It is the system of record for security telemetry in that it ingests logs, correlates events, triggers alerts, and often serves as the investigative hub for security analysts. Without pipelines, SOCs can’t fully optimize the full value of their SIEMs.
In 2025, what’s changing is not the necessity of the SIEM but the way we feed it. As security data pipelines evolve upstream, the SIEM remains the decision-making nucleus, ensuring we operationalize the telemetry that matters. The goal is no longer to ingest everything, it’s to ingest the right things. That means deduplicating, filtering, enriching, and routing telemetry through programmable pipelines. These pipelines don’t replace the SIEM, they make it viable again.
In this architecture, the SIEM becomes leaner but more strategic. It serves as the curated destination for high-fidelity, context-rich data, the kind that warrants long-term retention, correlation, and alerting. The SIEM, in other words, becomes smarter. Here is some data on the market share:


Trends in the SIEM Market
Dave Gruber, Principal Analyst at Enterprise Strategy Group shared
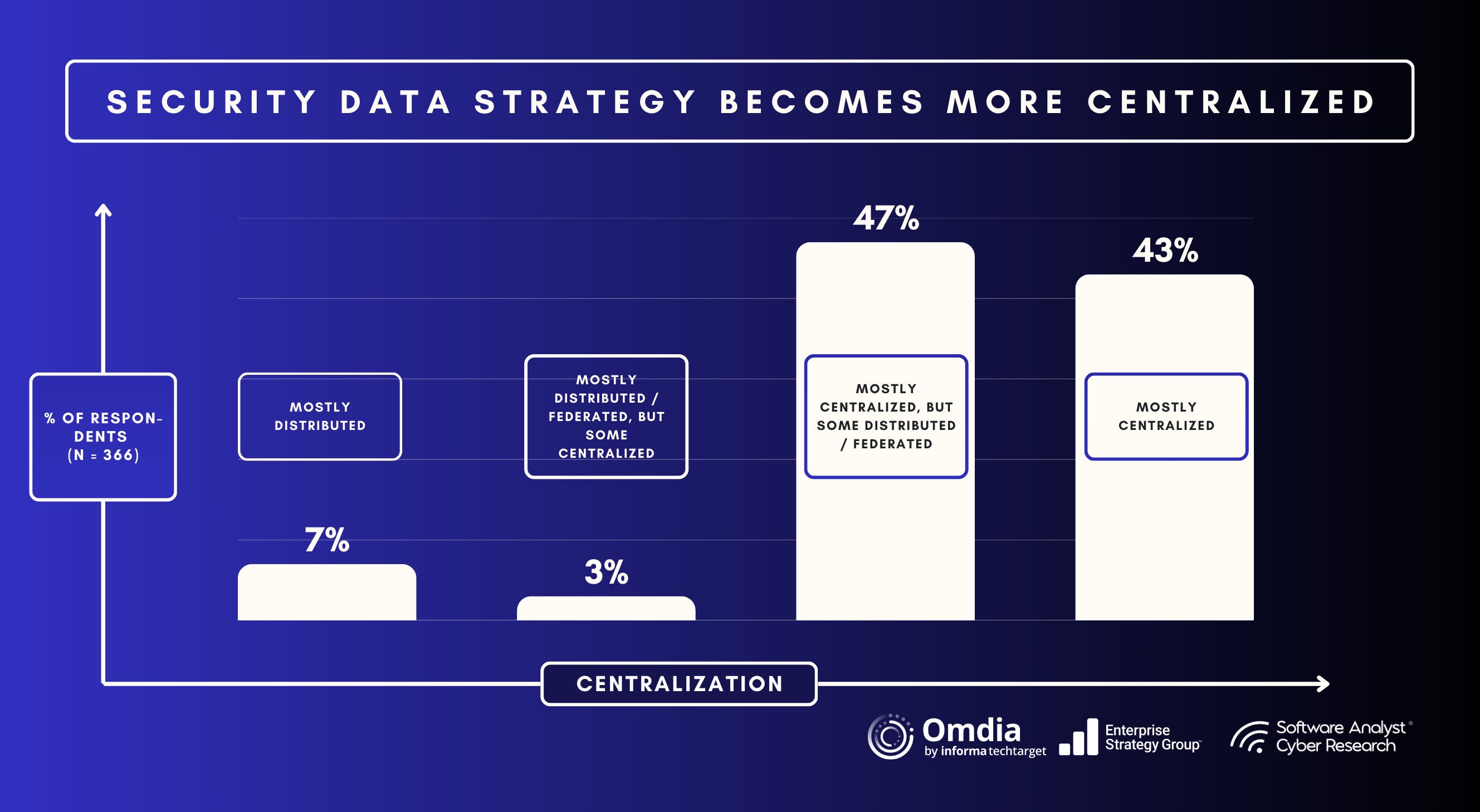
“Our recent SecOps research reports that a more centralized security data strategy is the vision for most, though progress is slow, with 43% reporting their strategy is mostly centralized today, with another 47% saying they are more centralized but still use distributed or more federated data (see Figure below)”.
Gruber further shared that “Despite ongoing tools consolidation efforts, multiple repositories continue to persist, with more than half (52% ) stating they maintain four to five, and an additional 23% saying they maintain six or more repositories for security data. Our research reports continued widespread usage of SIEM technology, with a vast majority reporting one or more SIEM solutions deployed today. However, organizations are paying significant attention to improving the security data layer, with nearly half either considering replacing one or more of their current SIEM solutions or planning to.”
Major SIEM Trends to Watch into 2025 as a Result of SDPP
SDPP Are Driving SIEM to SIEM + Data Lake to SIEM Migrations: Security Data Pipeline Platforms (SDPPs) are critical enablers of SIEM-to-SIEM or Data Lake-to-SIEM migrations by decoupling data sources from destinations. The process of routing telemetry directly to a single SIEM is extremely complex due to the different collection, storage, and analytics frameworks used by all the major SIEM providers above. As a result, organizations can send all logs and events through the SDPP, which acts as a central control plane. This allows for parallel data routing, simultaneously sending data to both the old and new SIEM, enabling testing, validation, and tuning without disruption. SDPPs also reformat and enrich telemetry to match the schema of the new SIEM, reducing ingestion errors and accelerating onboarding. During the transition, security teams can compare detections, performance, and cost metrics across both platforms. Once validated, they can cleanly cut over by simply updating routing rules within the pipeline. For Data Lake-to-SIEM use cases, SDPPs can read from storage systems like S3 or Snowflake, filter relevant logs, and stream them into the SIEM, which are useful for retroactive detection or backfilling context. In short, SDPPs eliminate the complexity and risk of migration by making telemetry portable, programmable, and resilient across any security stack.
Slower SIEM Migration, but More Data Lake Growth: The death of the SIEM has been over exaggerated. One of the main reasons SIEMs remain entrenched (despite concerns over cost and scalability) is their deep integration into compliance workflows. For many enterprises, SIEMs are the backbone of audit trails, log retention, years of detection logic, and alerting pipelines tied to regulatory mandates. These compliance-driven use cases are not easily ported to other platforms, which is why SIEM migration remains slower than the hype might suggest. Security teams often view SIEMs as “too critical to fail” for auditability and regulatory reporting. Security data pipelines are driving these enhancements.
Decoupling Storage from Analysis (“SIEM as Query Layer”):
Classic SIEMs were monolithic in that they would ingest and index all data internally and provide a search and correlation interface on top. This is changing. Modern approaches (sometimes referred to as security data lakes or lakehouse architectures) decouple the heavy storage layer from the analysis layer.
Security data pipeline vendors are increasingly allowing data to reside outside the SIEM (in cheap cloud object storage or data lakes) and letting the SIEM query it on demand. For example, Many of the vendors we discuss below have tiered storage. Or, Elastic and Splunk now have data tiering options; Microsoft Sentinel can query archived logs in Azure storage. This evolution means the SIEM doesn’t have to “own” all the raw data, alleviating the need to ingest everything (and hence reducing costs). Instead, the SIEM can focus on real-time indexing of the most critical data and rely on an external lake for historical or less critical data.
SIEM Augmentation Solutions Focused on Real-Time Detection vs Retention: The mission of SIEM is being refined. With so much data available, SIEMs are focusing on what they uniquely do well: real-time correlation, alerting, and investigation for recent events. For long-term analytics (e.g., multi-year data mining, big forensic investigations), organizations are augmenting with data lake data platforms from vendors like Databricks. SIEM vendors like Splunk have recognized this by offering federated search across archived data or integrating with data lakes. Essentially, the SIEM might become more of a real-time security analytics console, with its heavy backend abstracted. These “next-gen SIEM” often emphasize analytics speed (queries across 50% more data 150x faster) rather than simply ingesting more data. This implies the SIEM will rely on security data pipelines to pre-filter and shape data so that what it does store locally is high-signal for real-time use.
Future Trends of Security Data Pipelines in the SOC
Based on the key trends and developments happening the SIEM as a result of security data pipeline, below are key recommendations. These are our future predictions for how we see the space evolving:
Tighter Coupling with Threat Detection
As I’ve written in previous reports, like the 2024 Round-up, or within my AI SOC Reports. one of the biggest outputs or objectives within the SOC is the ability to efficiently identify what and where to look within massive data volumes to drive better Mean-Time-to-Resolution. MTTR still averages 4–5 hours as per research from Gartner. We believe that as a result, security data pipelines shouldn’t just collect or route this data (for cost reasons only) but increasingly help security teams make sense of this data quickly enough to drive other outcomes within the SOC. Pipelines need to play a more active role in detection, essentially blurring into the detection layer. We already see some vendors enabling Sigma rule execution within the pipeline layer, meaning they can spot known threat patterns on the fly.
In the future, pipelines might commonly include a library of detection rules or anomaly detectors that trigger alerts, before data even hits the SIEM. This could offload some work from the SIEM or XDR, or serve organizations that want lightweight detection at the edge (for example, filtering out obviously bad events and generating an alert directly to a SOAR platform).
The Rise of AI Data Engineer with Agents

AI/LLM will change how pipeline filtering is performed. The manual tuning of pipelines will give way to more autonomous data flows. We’re already seeing early signs: Onum’s natural language pipeline builder is one example of AI simplifying pipeline configuration. In the future, pipelines might automatically adjust filters and routing based on context and learning. Essentially, pipelines will become more self-optimizing. They might also intelligently enrich data, for e.g., an AI that reads all incoming VPN logs and highlights unusual login patterns without being explicitly programmed to do so. We might even see pipeline bots or agents (sometimes referred to as “agentic AI” in security operations) that act like junior data engineers, automating tasks like writing a new parser for a previously unseen log format or mapping fields to a common model.
We spoke to Vladislav B., a former SOC analyst, and he shared the following, which resonates with our thinking on the rise of AI Data Engineers and multi-agentic frameworks:
"Agentic AI is already reshaping day-to-day life in the SOC, freeing analysts from janitorial log work so they can hunt, triage, and respond in minutes, not hours. The next frontier is AI-driven SDPP orchestration, where a constellation of autonomous agents runs the data pipeline end to end. Building on insights from Brij Kishore Pandey and the ODSC community, multi-agent systems can now coordinate extraction, transformation, and loading with the same intelligence they bring to threat hunting."
A semi-autonomous or intelligent security-centric data pipeline stack might look like this:
Data Retrieval Agents – Extracting logs, telemetry, and threat intel from diverse, often noisy sources.
Transformation Agents – Normalizing, correlating, and enriching data with context for threat analysis.
Loading Agents – Delivering structured, prioritized insights into SIEMs, data lakes, XDR platforms, or Autonomous SOCs.
Orchestration Agents – Managing dependencies, workloads, and scaling security data pipelines in real time.
Analysis Agents – Detecting anomalies, surfacing indicators of compromise, and even auto-generating reports.
“The result is self-learning, self-healing data logistics: predictive workload forecasting, autonomous schema evolution, and natural language ‘SDPP copilots’ that harden governance while collapsing mean time to detect. Challenges remain, such as model drift, policy guardrails, and attacker evasion tactics, but the trajectory is clear. The future of SDPP is an intelligent control plane that adapts at machine speed and underpins every modern security operation.”
Security Data Platformization Breeding a New Architecture
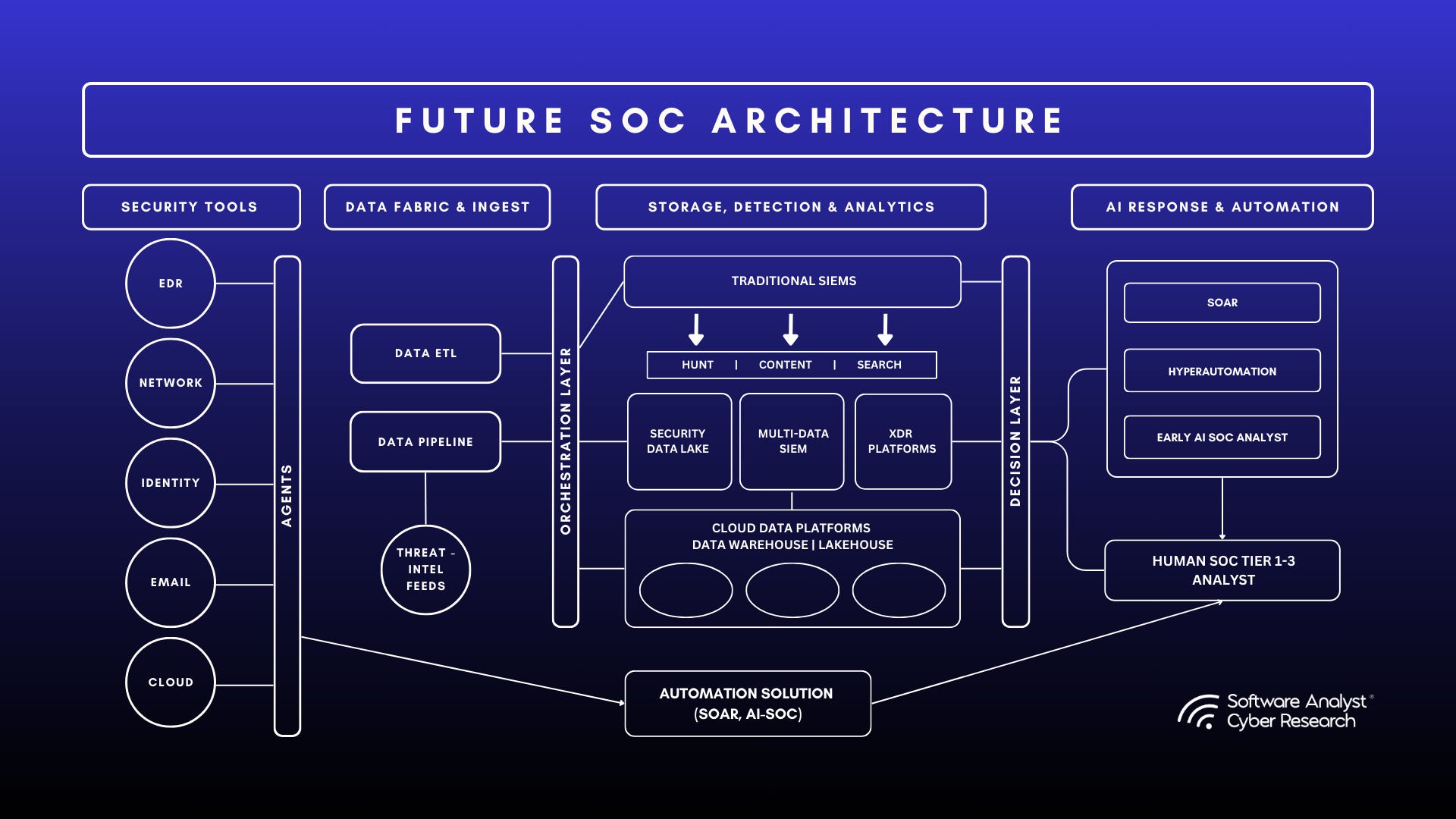
The term “security data fabric” has been coined to express an overarching layer handling security data across the enterprise. Earlier on we differentiated the concept as being different from security core use cases as we know it. However, in coming years, this concept may solidify around not implying that it is pipeline, but also an integration of data cataloging, search, and governance specifically for security data. We foresee pipeline tools adding more “fabric” features, for instance, a central schema registry for all security logs or a query interface to search data in motion.
By 2025 and beyond, a convergence between pipeline, data lake, and SIEM functions may produce a new class of platform. These platforms could let you ingest (pipeline), store (lakehouse), and analyze (search/detect) all in one integrated system, effectively the next-gen SIEM built on pipeline foundations. We see the beginnings: Cribl adding a lakehouse, Sumo Logic (a cloud SIEM) adding more pipeline-like processing, Splunk working on federated search.
The future might bring fully schema-agnostic query-optimized pipelines where you don’t even need to pre-define indices; you just collect everything in cheap storage and run fast queries on it via the fabric (this is close to the lakehouse idea). The fabric will abstract away whether data is “in the SIEM” or in the lake, since users just care that they can get answers. In such a future, the notion of SDPP might be embedded and invisible—the user interacts with a unified security data platform that handles ingestion through query. In other words, the pipeline becomes an assumed backend capability of a larger platform rather than a standalone product the SOC team deals with day-to-day.
Convergence of Observability and IT Data Pipelines with Security
The wall between “security data” and “operational data” will continue to crumble. Future pipelines will likely handle all types of telemetry in one unified flow, feeding both security and IT operations tools. Already, companies are talking about a unified “telemetry pipeline” for logs, metrics, and traces, encompassing APM (application performance monitoring) data alongside security events. The industry seems to be predicting that this will happen because double‑ingesting the same logs into an APM system and a SIEM is untenable when log volume is doubling every ~18 months. Security data pipeline vendors should only route one copy of data to many destinations, filtering or sampling as needed. Right now, SACR doesn’t see this trend immediately because security isn’t setup to handle APM data as it relates to trace-IDs, etc. We also believe security cares more about data integrity, quality of data, and signal (such as dwell time or MTTR) and this will continue to be the focus of SDDP solutions.
Consolidation vs. Independence
A classic question is whether the security data pipeline category will remain an independent standalone category or get absorbed into larger security platforms. There are two ways the industry can evolve:
SIEM (+ Pipeline Embedded): We see a case where the large and expensive SIEM providers are offering basic parsing and normalization capabilities. Some might soon consider offering tiered licensing—e.g., cheaper rates if data is ingested via their own pipeline that filters out junk (effectively acknowledging the pipeline in pricing). We’ve provided three examples of vendors within this category: Datadog, Stellar Cyber, and Anomali.
However, vendors like Splunk, Elastic and Palo Alto Networks have basic capabilities around this area. For instance, Splunk introduced Data Manager and Pipeline Builder features to help customers ingest cloud data with filtering and transformations. CrowdStrike launched CrowdStream (built on some Cribl features) to filter data from third-party sources into their platform. We also see cloud SIEMs like Sentinel offering ingestion filters or pre-processing rules. These vendors recognize the importance of simplifying the SIEM-to-SIEM migration using custom pipeline vendors. The trend is that SIEMs of 2025 start to offer their telemetry capabilities—much less sophisticated than the major providers.
SDPP (+ SIEM/Data Lake Embedded): Conversely, independent pipelines might start offering lightweight analysis features, encroaching into SIEM territory. This could lead to a convergence where what we traditionally think of as SIEM, UEBA, SOAR, and pipeline all merge into a unified platform or suite.
The Classic Dilemma: SIEM vendors historically didn’t create effective log reduction tools because it conflicted with their revenue model of charging by data volume. Going forward, especially with cloud-based SIEMs with flat or resource-based pricing (like SentinelOne’s offerings), we can expect more built-in pipeline features: things like the ability to normalize to OCSF on ingest, drop known benign events, or automatically enrich with threat intel. Overall, SIEMs are evolving to be more pipeline-aware, trying to eliminate the need for a separate product. That said, third party pipelines still often offer deeper capabilities and neutrality (since SIEM-native ones might push you toward that vendor’s ecosystem or have limitations). While some within the industry strongly believe the category will die off or converge, we believe the category is capable of becoming a standalone space because of the platform-agnostic approach and neutrality provided by a third-party.
Critical Capabilities: Security Data Pipeline Platforms
We believe cybersecurity platform companies can be created within this category over time.

Core Basic Capabilities:
Data Filtering, Reduction & Tiered Storage: This is the most basic and essential capability for minimizing noise and optimizing cost, enabling efficient storage and faster retrieval of security-relevant data.
Parsing, Schema, Normalization, Transformation: This ensures diverse data streams are structured and standardized, facilitating accurate correlation and analytics.
Data Enrichment (GeoIP, Threat Intel): This adds crucial contextual intelligence, significantly improving threat detection accuracy and response efficiency.
Redaction, Masking, Privacy Controls: This safeguards sensitive information, ensuring compliance with data protection regulations while enabling analytics.
Co-Pilot Capabilities, Pipeline as Code: This empowers agile, scalable, and repeatable data pipeline deployments through automation and code-driven management.
Futuristic Capabilities:
Agentic AI Data Engineer for contextual reduction and analysis
Multi-Agentic AI Data Engineer (Collector, Parser, Enricher)
Federated Search with Co-Pilot
Advanced In-Stream Detection Capabilities
Enterprise Cohesive Data Strategy Mapping
Full Market Ecosystem Breakdown
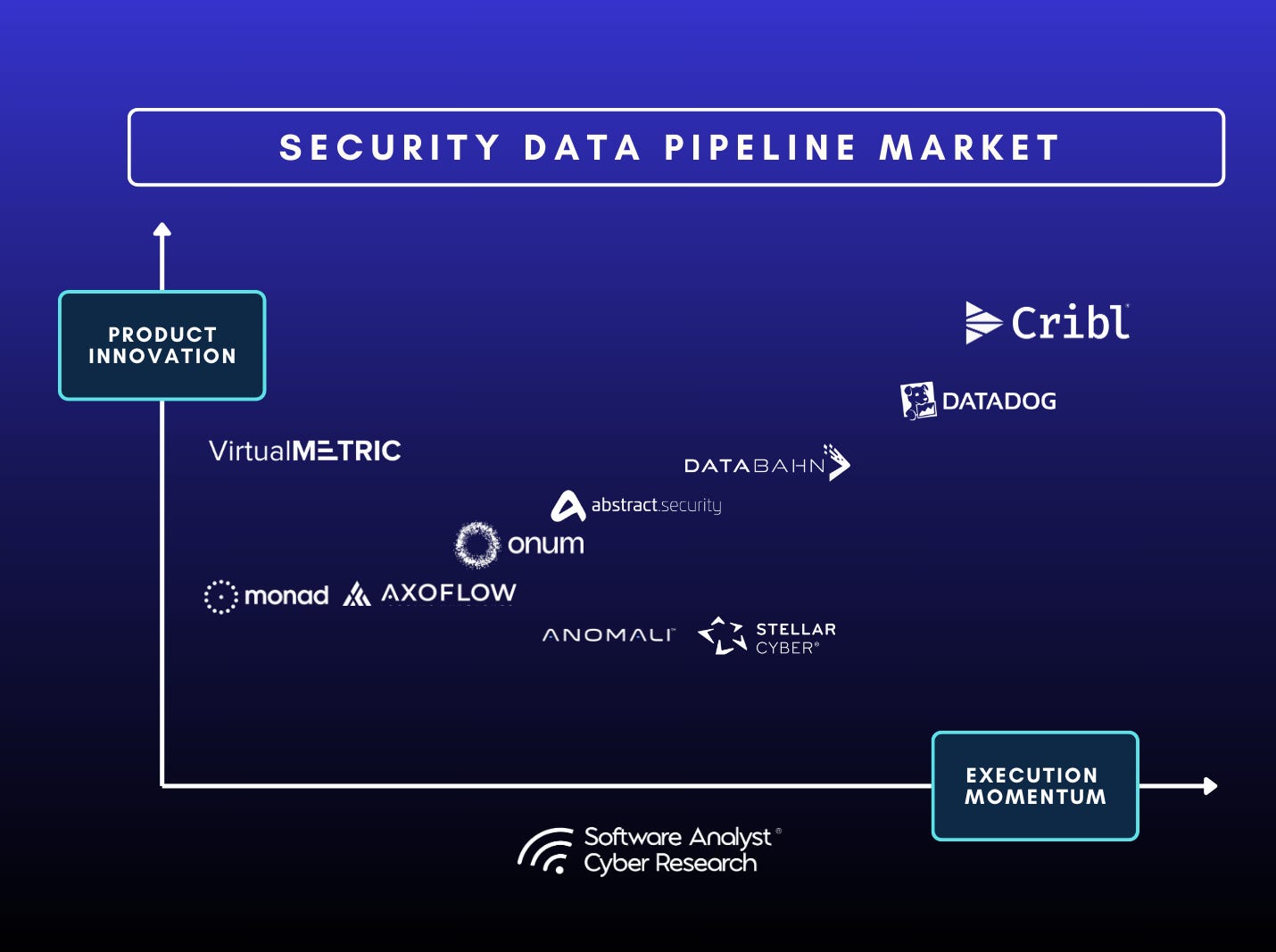
The following below is the full market ecosystem for the entire market. There are a significant and large number of vendors as the ecosystem has become increasingly fragmented with many new players. However, we’ve picked a few vendors from this list and narrowed down to the top 8 pure-play vendors that are market leaders based on the criteria we outlined below.
Vendor Analysis & Capabilities
Please visit this spreadsheet to see a detailed breakdown of the criterion we used to analyze the vendors. Below, we have some selective visual breakdown of some of the charts during our analysis, but see the spreadsheet for a detailed breakdown. Key criterion:
Product Innovation: This is a combination of core product capabilities, technical breadth and vastness of integrations.
Execution momentum: This is a combination of customer counts, crunchbase metrics, social media market thought leaders, what we heard from CISOs in our network and business metrics.
There is more data within the spreadsheet as mentioned.

The remaining report breaks down vendors areas where the following vendors are strong, areas to watch and my overall conclusions on their capabilities:
Pure-play SDPP Vendors:
Abstract Security
Axoflow
Cribl
DataBahn
Datadog
Monad
Onum
Virtual Metric
SDPP + SIEM++ Vendors
Anomali
StellarCyber
*** Please note the outlier, Datadog, since the company is a public company, but we evaluated specifically their observability pipeline. We’re ranking them throughout this report based on their adjacent products that compete against the following pure-play vendors.
Company Criterion Visual Breakdown
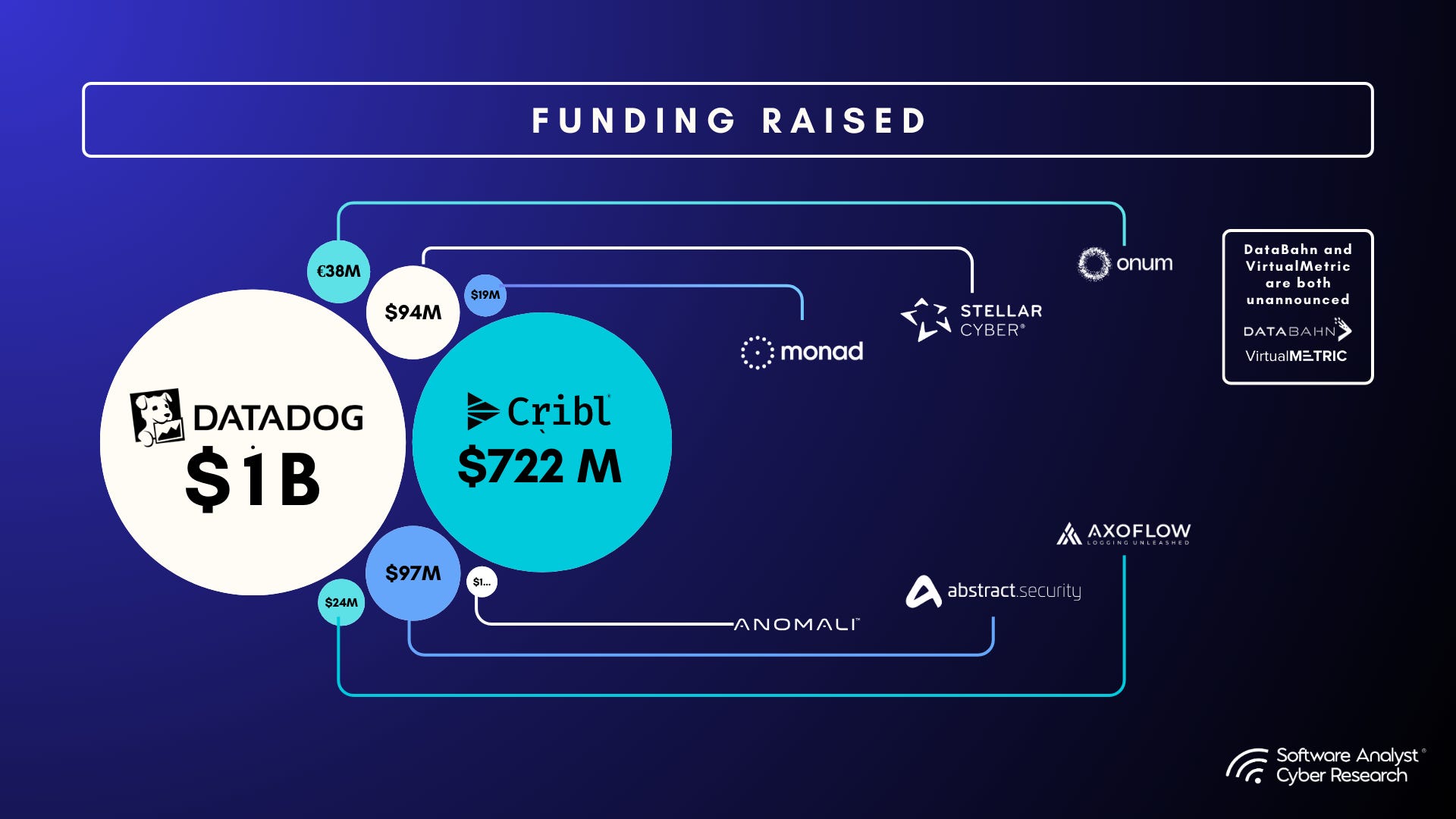
Crunchbase metrics
We extracted a number of key data points from Crunchbase

Funding rounds for vendors are depicted.
*Note: Datadog is a public company.
Some foundational capabilities evaluated:

Vendor Detailed Breakdown
Datadog
Datadog has steadily expanded its platform from core cloud monitoring and observability into adjacent domains, particularly security. Once known primarily as a tool for DevOps and infrastructure teams, Datadog is now actively building out capabilities for security engineers and SOC teams through products like Cloud SIEM, Threat Detection, and Observability Pipelines (OP).
Observability Pipelines is Datadog’s take on a modern SDPP layer, designed to help enterprises regain control over the volume, cost, and governance of telemetry data, especially logs, in complex hybrid and multi-cloud environments. Since its general availability 15 months ago, the product has been adopted by over 100 large enterprises. While OP today focuses on log data, its architecture and roadmap suggest broader ambitions to serve as a central control plane across logs, metrics, and traces.
Core capabilities
Cost Optimization : It enables fine-grained control over log volumes via pre-ingest filtering, deduplication, quota enforcement, and conditional routing. Customers have reported reducing logging costs by over 50% and can offload noisy or low value logs to cold storage like AWS S3, GCP, or Azure for on-demand retrieval. Flexible routing enables dual shipping of logs to different destinations (e.g., Datadog and Splunk), reducing lock-in and simplifying migrations. For organizations moving between tools or modernizing infrastructure, OP becomes a valuable bridge.
Compliance Enforcement: From a compliance and security standpoint, Datadog includes a Sensitive Data Scanner, supporting over 90 prebuilt detection rules for redacting or masking PII, API keys, and secrets. Enterprises benefit from integrated RBAC, audit trails, and Live Capture tools that provide governance and visibility over pipeline changes and telemetry flow.
Architectural Flexibility : Datadog supports 150+ log formats, GeoIP parsing, enrichment tables, and more—all of which improve searchability, root cause analysis, and incident response workflows. The platform’s hybrid deployment model (SaaS control plane with on-prem agents) serves regulated sectors well, allowing control over data residency and compliance.
Areas to Watch
Despite strong log-handling capabilities, OP is still evolving toward full observability coverage. Native support for metrics and traces remains on the roadmap, limiting its immediate use as a single platform to control all telemetry types across security and observability.
The hybrid deployment model, while ideal for compliance-heavy enterprises, may introduce unnecessary complexity for leaner teams or smaller organizations. Although OP integrates with a wide array of third-party tools, Datadog’s platform-centric approach means the product is most powerful when used in conjunction with the broader Datadog stack.
The acquisition of the Vector team gives Datadog a strong foundation in high-performance data collection. Future enhancements are expected to deepen AI integration for real-time enrichment, filtering, and anomaly detection. Continued alignment with industry standards like OCSF, along with its vendor-agnostic routing capabilities, reinforces OP’s value as a flexible and forward-looking telemetry solution.
Analyst Take
Datadog OP is differentiated by its integration with a full-stack observability and security platform. For Datadog customers, it offers a single control plane to filter, transform, enrich, redact, and route telemetry data without needing standalone scripts, YAML files, or third-party pipeline infrastructure.
Datadog’s dual focus on automation (AI-based parsing and quota management) and compliance (redaction, access controls, auditing) is well aligned with the needs of enterprises navigating regulatory complexity, rising telemetry volumes, and mounting observability costs.
The strategic vision for OP is to become a unified control layer not only for logs, but for metrics, traces, and potentially user-generated or application-layer data. If Datadog delivers on this roadmap, OP could evolve into a core data-routing backbone across observability, security, and compliance.
As an analyst, I’ll be watching closely to see how OP matures into that role. Its potential to displace legacy telemetry gateways and provide intelligent, governed, and context-aware telemetry flow is real. Datadog’s native presence in cloud infrastructure gives it a meaningful head start.
SDPP
Abstract Security
Abstract Security is a security data pipeline and analytics platform designed to help organizations reduce their dependence on traditional SIEMs. It focuses on shifting detection left i.e. improving detection speed while managing the cost and complexity of handling security telemetry. The platform combines telemetry pipeline features such as data reduction and aggregation with real-time streaming analytics for threat detection, and offers a “no-code required” intuitive interface that reduces the need for deep technical expertise.
One of Abstract’s core features is its ability to process and analyze security data in real time. It supports early stage filtering and transformation of telemetry, allowing security teams to act on relevant data faster. The system’s natural language interface allows users to build pipelines and conduct analysis without writing complex queries, which is particularly useful for teams that do not have dedicated data engineers. Abstract also uses artificial intelligence for enrichment, correlation, and analytics summarization, applying automation to areas that typically require significant manual effort.
Core Capabilities
AI-Augmented Streaming Analytics and Detection: Abstract supports streaming detection and data enrichment using both internal and customer provided threat intelligence feeds. Its pipeline is designed to handle high volumes of data and supports advanced filtering to focus on signals from cloud and SaaS environments. This approach helps organizations avoid sending excess data into downstream platforms and supports more efficient alerting. Based on our interactions, their ability to ingest tens of millions of IOCs and apply enrichment rules in-stream provides strong scalability for both MSSPs and large enterprises.
Data Redaction + Filtering: Another useful capability is the ability to redact sensitive data early in the pipeline. Teams can configure custom rules to remove credentials or other confidential information before it is processed or forwarded. This helps reduce compliance risk and improves control over what data is stored or shared.
SIEM Replacement, Migration Or Data Lake for Storage / Threat Hunting: Abstract provides a data lake model with tiered storage options that complements its streaming analytics engine. While its core focus is real-time detection, the inclusion of a data lake enables more traditional retrospective threat hunting use cases. This allows organizations to run queries on historical data when needed, without depending entirely on a traditional SIEM.
With Abstract’s tiered data lake model (real-time, warm, and cold storage), organizations gain flexibility without compromising retrieval speed or long-term storage costs. Importantly, the platform is already being used by multiple MSSPs and enterprise customers as a full SIEM replacement, not just as an augmentation layer. This means Abstract handles both data ingestion and detection/analytics functions typically expected of a SIEM but does so in a more modern and cost-efficient manner. Abstract is also being used as a bridge tool during SIEM migration efforts, making it a transitional platform for teams moving away from legacy systems like Splunk or ArcSight, while enabling real-time detection in parallel.
Areas To Watch
Further Enhancements To Natural Language Analytics Descriptions: Abstract is advancing into AI-generated explanations of analytics findings, which could become a key differentiator as SOC teams increasingly seek human-readable and explainable insights. Currently optimized for data management and real-time detection, Abstract plans to extend into deeper fraud, insider threat, and behavior-based detection use cases.
Contextual Detection Engineering: Abstract is developing tools to make detection engineering more sophisticated and precise. By leveraging Sigma rule conversion and building an advanced streaming correlation engine, the platform enables teams to write complex, multi-stage detection rules. This supports logic like tracking sequences of events (A, then B, then C) and creating incidents automatically when threat intelligence matches occur.
Analyst Take
Overall, we were impressed with Abstract Security’s capabilities as a SOC pipeline and threat detection platform that goes beyond SDPP functionality. Abstract is positioning itself beyond traditional data pipelines by integrating advanced threat detection directly into the data streaming process.
Its streaming analytics include real-time correlation, behavioral anomaly detection, and threat intelligence matching, enabling contextual intelligence at the point of ingestion. By analyzing and acting on data as it flows, Abstract supports a more proactive detection posture, aligned with the needs of modern SOCs facing alert fatigue, data sprawl, and cloud-native complexity.
Its long-term trajectory, focused on reducing engineering burden while increasing detection efficacy, positions it well for the current threat landscape.
Axoflow
Axoflow is an early-stage company founded by the creators of syslog-ng and the Kubernetes Logging Operator. Originally based in Europe and now operating in the US, the company is building a next-generation observability security data pipeline platform tailored for security data. Its focus is on reducing operational complexity and improving log quality before data reaches downstream tools such as SIEMs, data lakes, or observability platforms.
The platform is designed to automate, simplify, and monitor telemetry infrastructure across hybrid environments, supporting both cloud and on-premise deployments. It helps organizations improve data reliability while lowering infrastructure and processing costs.
Core Capabilities
Axoflow’s platform is composed of three key components:
Axoflow Management Plane: This provides centralized, vendor-agnostic control over telemetry with high visibility and reliability.
Axoflow Data Plane: This efficiently delivers telemetry to SIEMs and observability backends.
Axoflow Telemetry Intelligence: This leverages AI-assisted capabilities to filter, classify, enrich, and transform telemetry data for optimized analytics performance.
Analysis
Intelligent Data Parsing and Classification: Axoflow introduces a unique data ingestion architecture via its AxoRouter component, which automatically classifies, parses, and routes logs based on their structure, eliminating the need for static source configuration. Rather than relying on co-pilots or manual parsing, Axoflow embeds AI to productize parsing logic for over 150 log types (e.g., Palo Alto, FortiGate, Windows), with new formats added biweekly. This approach enables organizations to adapt quickly to vendor log format changes without breaking detection rules or requiring extensive pipeline reconfiguration.
Pipelines with Built-In Reduction: Axoflow follows a modular, opinionated pipeline architecture, where core tasks like parsing, schema mapping, and reduction are handled by the platform itself. Users are only responsible for select enrichment or transformation rules. This design leads to significant operational savings of up to 70% fewer manual rules compared to larger solutions, and reported log volume reductions of 25–70%, especially for verbose logs like Windows or redundant formats (e.g., text + XML).
Real-Time Topology-Aware Observability: The platform provides visibility across physical (source mapping), analytical (team and resource usage), and pipeline (flow logic and behavior) views. It monitors for telemetry gaps, such as when firewalls silently stop sending logs or when packet drops occur at the kernel level, insights typically not detected by traditional tools. This observability layer empowers SOCs to reduce root cause analysis times and maintain confidence in end-to-end telemetry flows
Integrations and Edge-First Processing: Axoflow processes telemetry close to the source, reducing upstream transfer needs and minimizing SIEM ingestion costs. It supports over 100 data sources and integrates with key platforms like Splunk, Microsoft Sentinel, and Elastic/OpenObserve. Logs are pre-processed into destination-specific formats, avoiding the need for external processing tools such as Splunk TAs or Cribl post-processing packs.
Areas to Watch
Axoflow is one of the earliest vendors within the space as a seed-stage company. We will be on the watch on the robustness of their capabilities to match with earlier vendors within the space over time and we. We will be on the lookout for the robustness of their GTM efforts, but so far, we like their technical capabilities around AxoRouter.
Analyst Take
Axoflow stands out in a crowded security pipeline market by automating complex parts of telemetry management including data classification, parsing, enrichment, and reduction without requiring brittle regex rules or constant rule writing.
Its opinionated, schema-aware pipeline architecture is built for scale, supporting environments ingesting up to hundreds of TBs of log data per day. This design offers value for teams managing high-volume security telemetry and organizations dealing with log format instability.
Axoflow has an automated control plane accessible to both analysts and engineers. If the company continues to invest in automation, observability, and enterprise-grade features, it has the potential to become a major disruptor in the SDPP space.
Cribl Security
Cribl is the most prominent company within the security data pipeline market, with the highest amount of funding, totalling over $600M as of Aug 2024 and recently surpassed $200M ARR.. Cribl was founded in 2018 by Clint Sharp (CEO), Dritan Bitincka (CPO), and Ledion Bitincka (CTO), all of whom previously worked at Splunk.
Cribl offers a suite of modular products designed to help enterprises gain visibility and control over the flow of telemetry, observability, and security data across increasingly complex hybrid and multi-cloud environments.
Cribl is built for the largest enterprises and has been developed to scale depending on the complexity of their clients. It has the broadest amount of offerings and capabilities across all the vendors. Cribl supports hybrid, cloud, and on-prem environments, appealing to enterprises with data sovereignty and localization requirements, and complex deployment scenarios.
Core Capabilities
Cribl Stream: The centerpiece of the Cribl suite, enabling security and observability teams to ingest, route, transform, enrich, and reduce telemetry data before sending it to downstream platforms.
Cribl Edge: Designed to operate closer to where data is generated, such as endpoints, applications, and edge nodes. It supports distributed collection and local filtering before sending telemetry upstream to Stream or other systems. Edge also supports unified management across operating systems and integration with Cribl Search.
Cribl Search: Offers search in place capabilities, allowing users to query data directly in object stores like AWS S3 or Azure Blob, APIs, and other data locations without first indexing or ingesting it into a centralized data warehouse or SIEM. This federated model decouples compute and storage, enabling cost-effective long term access while reducing reliance on hot storage. AppScope is also available as their SaaS delivery platform.
Cribl Lake & Cribl Lakehouse: Cribl Lake allows users to store raw or transformed data in open formats using commodity cloud object storage. It is designed for long-term retention, Replay with Cribl Stream, and downstream integration, as well as integration with Cribl Search. Cribl Lakehouse, launched more recently, offers much better query performance over high volumes of data, often 5-25x faster than Cribl Lake. It is designed as a columnar storage and analytics layer optimized for fast querying and frequent access to prioritized data.
Cribl Copilot & Cribl Cloud: Cribl Copilot is an AI-powered assistant that helps users set up, troubleshoot, and optimize Cribl environments using natural language. It offers a human-in-the-loop system for building pipelines and querying data. It supports automated regex generation, pipeline setup, and error debugging. This is especially useful for large enterprises with distributed SOC teams. Alongside Cribl Cloud, they form a flexible, vendor-neutral data pipeline layer that can sit between data sources and analytics platforms like Splunk, Datadog, or Elastic.
Areas to Watch
Cribl was built for the largest and most sophisticated enterprise SOCs in the world. With this comes a breadth of capabilities that might not be suited for mid-sized companies, but based on our discussions with them, they are further enhancing the experience down market, especially for organizations without strong internal engineering teams.
While Cribl Copilot aims to alleviate this, customer feedback continues to highlight a learning curve in the platform’s UX. The company’s primary audience is large enterprises, so ease of use and out of the box value for SMBs may be limited in the near term since these customers don’t experience the same level of data volumes. However, it’s important to note that Cribl works extensively with a wide number of service providers who in turn work with many SMBs on the market.
Another area to watch is how Cribl positions itself in a market that is increasingly converging between observability and security analytics. While Cribl does not want to be labeled a SIEM, its capabilities for querying, indexing, and compliance reporting begin to overlap with some traditional SIEM functions.
Analyst Take
Cribl has been the significant dominant player over the past few years. Cribl has earned its position as a pioneer in the security data pipeline space, and they remain one of the most mature and widely adopted platforms in the market.
However, over the last 12–18 months, we’ve seen a rapid number of new vendors and startups emerging to solve a similar problem, targeting different aspects of the market. Many of these are built with AI-native architectures and tailored user experiences. It’s still important to note that Cribl’s strongest advantage lies in its hybrid deployment support, its enterprise capabilities, robust partnership network, and its vendor neutral philosophy. These traits position Cribl as a good fit for organizations that need to unify fragmented telemetry architectures without consolidating to a full-stack observability or SIEM vendor.
As the market matures, Cribl’s challenge will be maintaining its pace of innovation while continuing to simplify complexity and expand its usability beyond elite enterprises. Its leadership position is still defensible, but the window for differentiation is narrowing as more players rush into the growing SDPP segment. Future success will depend on how well Cribl continues to rapidly innovate and leverage its distribution to extend its capabilities.
DataBahn
DataBahn was founded by the same team that created Securonix, who have spent over two decades building for the SOC and possess a deep understanding of the pain points faced by modern security operations. Based on extensive external metrics—including enterprise customer base, Crunchbase rankings, social media presence, and market momentum, we can say DataBahn is emerging as the second-leading player in this market. We were able to validate a few metrics around the fact that the company has achieved rapid 2x growth in its most recent quarter and now serves over 15 Fortune 500 enterprises that have standardized on the DataBahn platform for their security data pipeline modernization. Currently, more than 10 enterprise clients use DataBahn to route data to multiple SIEMs simultaneously. Customer feedback from several Fortune-ranked companies indicates that DataBahn has displaced major pipeline competitors due to its faster value realization, built-in security content, and superior long-term TCO.
DataBahn's core strength lies in its pipeline-first approach to SOC data operations, which cuts costs for the legacy SIEM’s that dominate today’s market. They’ve placed a big emphasis on simplicity through accessible interfaces, faster data access, and lighter deployment requirements. This gives them an edge for leaner security engineering teams that lack dedicated data engineering resources.
Core Capabilities
DataBahn enables customers to preprocess, enrich, and reduce data before it ever reaches the SIEM. Its most notable feature is the inclusion of predefined reduction packs for nearly every major data source (EDR, firewall, DLP, etc.), allowing security teams to quickly strip out non-essential telemetry and preserve only what is relevant for investigations or audits. This is particularly valuable in environments like Microsoft Sentinel, where unoptimized data inflates both costs and query complexity.
Hybrid Deployment Modes: DataBahn supports both agentless and agent-based deployment modes, offering native integrations for customers that prefer a zero-install footprint while also providing agent-level telemetry capture for organizations that require more granular control. When deployed alongside EDR agents or other endpoint tools, the platform can interact with raw telemetry for enhanced visibility and data fidelity.
Custom Table Routing: The platform also supports custom table routing and data transformation, reducing the number of resources required to manage the SIEM. With one customer, for example, analysts were able to reduce 50-line kql queries down to just 5 lines, demonstrating not just better data quality but faster time-to-response.
Advanced Memory Layer: A core differentiator in its roadmap is Data Reef, DataBahn’s emerging contextual memory layer. This feature enables the platform to maintain a long-term understanding of customer-specific data behaviors and trends. By persistently tracking how telemetry evolves and how it is acted upon, Data Reef provides a foundation for adaptive enrichment, retrospective analysis, and more relevant AI-powered recommendations. This ensures the pipeline not only processes data efficiently, but also learns and improves over time.
Enrichment: Beyond its core security data pipeline functionality, DataBahn offers a growing set of features that emphasize threat-informed enrichment and data transformation intel. The platform is used not just as a routing layer, but as a strategic asset for threat research teams to help identify and remediate gaps mapped to the MITRE ATT&CK framework. This visibility is driven by real-time data streaming and the ability to transform telemetry across heterogeneous data models in-line, rather than post-ingestion.
Areas to Watch
Although still in its early stages, Reef introduces LLM-native interfaces to pipeline data, sitting on top of the observability layer and allowing SOC analysts to ask plain-language questions like “show me all suspicious IPs in the last 7 days,” without writing complex KQL or regex.
The tight coupling with historical case data and context from SOAR tools makes Reef distinct. In future versions, it will be able to correlate real-time telemetry with past incident outcomes, automatically flagging likely false positives or surfacing similar attack patterns. It supports context-aware enrichment, drawing from integrated threat intelligence feeds (e.g., VirusTotal) and case history to recommend pipeline rules, flag anomalies, and explain the actionability of different data types. These capabilities help reduce reliance on senior engineers and accelerate onboarding for new SOC analysts.
Analyst Take
When speaking to customers, we learned that DataBahn’s advantages were its simplicity, engineering velocity, and tangible ROI. A CISO specifically highlighted DataBahn’s engineering team as being agile with an emphasis on quick iteration and responsiveness. We believe that their new Data Reef will be impactful. This is their new LLM-native insight layer that allows analysts to run complex investigations via natural language queries (e.g., “Show me all suspicious logins”)—no KQL or regex required. Looking ahead, DataBahn aims to expand its AI-Native pipeline search with centralized ROI dashboarding that quantifies ingestion savings and data reduction impact, all within the observability layer itself.
Monad Security
Monad has built its SDPP as a data operations control plane for security teams. As an early mover in the space, Monad has built a reputation for its structured data pipeline orchestration and scalable data engineering capabilities tailored for security use cases.
Monad integrates deeply into use cases around SIEM optimization by ingesting and routing raw or processed logs. It enables teams to filter, normalize, reduce, and route data to SIEMs and other destinations. Its flexibility allows conditional routing logic, normalization, redaction, and enrichment at ingestion, turning unstructured logs into structured, high-fidelity security artifacts.
The platform also supports vulnerability management use cases and is increasingly used by other cybersecurity vendors to handle messy data prep and transformation tasks that precede detection or response logic.
Core Capabilities
Kubernetes-Native Architecture: Monad’s core differentiator is its ability to operate within a Kubernetes-native, cloud-agnostic architecture that scales horizontally. This architectural flexibility allows it to serve hybrid infrastructure setups (on-prem + cloud) more natively than many competitors, while maintaining cost control through Kubernetes-native elasticity.
Integration Breadth and Flexibility: Monad currently supports over 80+ integrations, connecting with a wide variety of log sources, cloud platforms, and destinations. Universal connectors (e.g., S3, HTTP) offer flexibility to support additional sources and destinations not currently supported out of the box.
Engineering Velocity and Custom Pipelines: We liked the engineering velocity at Monad. Their ability to spin up new connectors and support custom enrichment pipelines quickly is critical for enterprises seeking fast time-to-value.
Developer Enablement with SDKs: Monad offers Go and Python SDKs, making it one of the most developer-friendly and scalable security data pipeline platforms available—especially for teams looking to programmatically manage pipelines and integrations.
Areas To Watch
While technically robust, Monad is still expanding its user interface and accessibility for less technical users. The current experience is best suited to users with data engineering or DevOps familiarity. Improving visual pipeline creation and operational transparency (e.g., debugging, pipeline health metrics) will be key to driving adoption among SOC analysts and detection engineers.
Monad is exploring the integration of AI-assisted pipeline creation, potentially allowing users to define workflows via natural language or pre-trained logic. This mirrors broader trends in observability (e.g., Cribl’s Stream AI) and could lower the barrier to entry for teams without in-house data engineering skills.
As Monad moves toward broader enterprise adoption, it will also need to extend its value beyond SIEM optimization, including the expansion of pre-built pipelines and integrations that map to common detection use cases.
Analyst Take
Monad is an emerging player redefining how security teams manage and operationalize data. We were particularly impressed by its transformation and parsing capabilities, which apply the same rigor and performance principles that observability pipelines brought to DevOps—but with a security-first mindset.
Monad builds a modular pipeline foundation for modern security workflows, which is especially critical in today’s hybrid and multi-cloud environments, where SOC teams are overwhelmed by noisy and inconsistent log data. Monad gives teams the ability to shape and streamline telemetry at scale, improving detection fidelity while minimizing the volume and cost of data sent to SIEMs and other downstream tools.
In summary, Monad is well-positioned as a neutral, cloud-native data control plane that enables downstream tooling to operate more efficiently. The company’s objective to serve as the connective tissue between raw telemetry and systems like SIEMs and data lakes reflects a modern, scalable approach to SOC infrastructure.
Onum Security
Onum delivers a real-time data intelligence platform purpose built for security and IT teams to reduce, enrich, transform, and route telemetry across cloud, hybrid, or on-prem environments. Founded in 2022 by entrepreneurs with experience in security and observability, Onum addresses a critical enterprise challenge: the cost, complexity, and latency of managing high volume security telemetry at scale.
Core Capabilities
Real-Time, In-Stream Data Processing: Onum processes telemetry data, including logs, metrics, events, and traces, in real time using a stateless, in-memory architecture. This eliminates the need for intermediate storage or post processing, allowing teams to act on data within milliseconds. Its real-time capabilities extend to inline enrichment using threat intel, asset data, or geo-IP, while supporting schema normalization (e.g., OCSF), masking, and deduplication, all during ingestion.
What sets Onum apart is its ability to move detection, transformation, and routing upstream into the data stream. Instead of relying on legacy SIEM pipelines that operate post-ingestion, Onum processes data closer to the source. This shift has delivered measurable results: customers report up to 70% faster incident response, 50% lower storage costs, and 40% less ingestion overhead. By sending only high-fidelity, enriched data to platforms like Splunk, Sentinel, or BigQuery, Onum improves both operational efficiency and telemetry economics.
Intuitive Drag-and-Drop UI :
A defining feature is Onum’s visual interface, which enables users to construct and adjust pipelines with drag-and-drop controls, real-time previews, and live feedback. Teams can configure enrichment, parsing, transformation, and routing logic without code. Unlike traditional tools that require brittle scripts or deep engineering knowledge, Onum’s interface democratizes pipeline creation. SOC analysts, security engineers, and operations teams can adapt workflows without writing a single line of code. An integrated AI assistant further streamlines this process by recommending configurations, validating logic, and suggesting performance optimizations, reducing errors and accelerating time-to-value.
This UI-first approach isn't just about usability, it's about agility. Teams can test changes instantly, roll back versions, and monitor pipeline health through metrics like latency, error rates, and throughput. The drag-and-drop UI is often cited in customer feedback as a major productivity gain, especially for teams looking to reduce the overhead of managing brittle scripts or hand-coded pipelines.
Enrichment & Transformation in Transit
Onum performs contextual enrichment directly in the pipeline, enriching raw telemetry with geo-IP, threat intelligence, and asset metadata. It supports real-time schema normalization and format restructuring (e.g., JSON, CSV, key/value) to ensure data is actionable and compatible with downstream analytics tools, improving overall threat context.
Flexible Pipeline Creation with AI Assist
Beyond the UI, Onum includes AI-powered support for building and optimizing pipelines. It guides users through field mappings, transformation logic, and routing decisions. Rollback support, telemetry visibility, and error tracking reduce dependence on specialized engineering and make pipeline management more resilient.
Broad Integration Ecosystem
With over 50 integrations across SIEM, SOAR, observability, and cloud tools, Onum supports agentless ingestion and protocol-aware output. Input options include syslog, HTTP, Kafka, and APIs; output destinations include Splunk, Sentinel, BigQuery, Elastic, Datadog and more. This flexibility reduces vendor lock-in and simplifies modernization efforts.
Areas to Watch
Additionally, while Onum offers broad integrations and pipeline strengths, it lacks depth in native detection, response, or investigation capabilities, which are central to full-spectrum SOC tooling. It should be seen as a telemetry control plane rather than a security analytics replacement. While Onum supports metadata enrichment (e.g., geo-IP, asset tags), the integration of live threat intelligence feeds for real-time correlation is still on the roadmap. SOCs looking for contextual threat detection will still rely on downstream SIEMs or threat engines. We anticipate the depth of their AI-generated pipeline creation which is promising, but not deeply mature.
Analyst Take
Onum is emerging as a strong player in real-time telemetry pipelines, not by becoming another SIEM or data lake, but by rethinking the data lifecycle itself. Its core innovation is in-stream enrichment, transformation, and routing that shifts control to where the data originates. Its blend of technical depth and usability, especially the visual UI and integrated AI, allows teams to respond faster while reducing complexity and engineering load. Customers benefit from lower storage and ingestion costs and faster operational response. Their current trajectory and architecture suggest it is well positioned to become a core control plane for security data pipelines in the modern SOC stack. For security and IT teams looking to manage telemetry volume, cost, and complexity, Onum represents a modern platform built for real-time control and clarity in the SOC.
VirtualMetric
VirtualMetric is an early European based vendor entering the SDPP market with a highly focused product strategy centered on enhancing Microsoft Sentinel. Its core platform, DataStream, provides an agentless and vectorized telemetry pipeline designed to reduce costs, enrich log data, and enable flexible routing, primarily for security operations teams leveraging Microsoft’s ecosystem.
The platform stands out for its deep Sentinel-native integration, a custom log format (VMF-3), and a processing engine optimized for parallel performance and role based data control. With a technically sophisticated design, VirtualMetric is built to solve ingestion, routing, and cost challenges for Sentinel users.
DataStream’s tight integration with Sentinel helps lower ingestion costs by up to 80 percent through pre-ingest filtering, transformation, and compression. This reduces noise, optimizes log formats, and enables plug and play support for ASIM-compliant logs.
Core Capabilities
Sentinel-Native Optimization : VirtualMetric is one of the few SDPP vendors purpose-built for Microsoft Sentinel to reduce unnecessary data via parsing, filtering, and transformation pre-ingest. Its vectorized pipeline engine uses all available system cores to process and compress data with up to 99 percent efficiency, improving speed and lowering transfer costs.
They solve issues around log categorization into ASIM schemas, which helps improve alignment with Sentinel’s analytic rule engine and supports seamless routing to Azure Data Explorer and Blob Storage for long term compliance, threat hunting, and performance offloading. They also chose compatibility with Elastic pipeline syntax to avoid vendor lock-in and reduce learning curves.
Ultra-Efficient Pipeline Engine and Format (VMF-3): VirtualMetric’s performance stands out due to its proprietary VMF-3 format, which claims to be 10x faster than JSON and 99.9 percent more compressed, outperforming even Parquet and Apache Arrow. This makes them highly ideal for storage and low-latency transport.
Their engine is fully vectorized and can process multiple datasets using all available CPU cores. The same engine powers their InfraMon product for log monitoring, where it achieves 2TB per day throughput with just 2 servers, compared to 250GB per day with 8 servers on legacy tools. For MSSPs or enterprises pushing high volumes of telemetry (1–10TB per day), this cost/performance benefit is hard to ignore.
Agentless, Source-Aware Collection : With their roots in infrastructure monitoring, VirtualMetric supports agentless log collection across 20+ OS and device types. It supports remote pulling of DNS logs, EDR telemetry, Windows event logs, Linux audit logs, and more.
They have automatic routing of logs into different data destinations based on content (e.g., threat intel logs to ADX, compliance logs to Blob Storage, security signals to Sentinel). “One important distinction is that the company categorizes datasets at the source, not just routes them.”
Zero Data Loss & Pipeline State Awareness: VirtualMetric uses a Write-Ahead Log (WAL) architecture to persist all routing and transformation states. This ensures data resiliency, which is particularly important for regulated industries requiring compliance assurance and audit trails.
Areas to Watch
While VirtualMetric can technically route to Splunk, Elastic, or Google Chronicle, these integrations are not as seamless or production-hardened as those for Sentinel. The company’s strategy is clearly to dominate a single ecosystem first as it seeks to expand. They are navigating ways to work in hybrid SOCs where Splunk and Sentinel coexist. As they expand cross-SIEM maturity, this will allow them to fill broader roles in multi-platform environments.
Analyst Take
VirtualMetric is a next-gen SDPP vendor that is opinionated in its product design and focused on a single platform, enhancing Sentinel at scale. In a space where most vendors try to serve broad use cases, VirtualMetric’s depth in Microsoft integrations, paired with high-performance pipeline infrastructure and zero-loss architecture, gives it a strong early mover advantage. If the team delivers on customer success and expands support for dual SIEM deployments, VirtualMetric could emerge as a credible option for Microsoft-centric security environments and a challenger to established players.
SIEM ++
Anomali
Anomali is a notable example of a company evolving from a niche threat intelligence provider into a fully integrated, cloud-native security data/operations platform. In recent years, the company has quietly re-architectured itself into a next-generation SIEM platform, built for the demands of modern security operations.
At the heart of Anomali’s evolution is a recognition that the future of security operations lies not just in detection, but in full telemetry control from ingestion and transformation with Copilot capabilities, across analytics and threat response. The company was founded by Hugh Njemanze, known in Silicon Valley as the “Father of SIEM” and a pioneer in solving big data challenges for security and IT. From day one, Anomali was purpose-built to ingest and correlate telemetry (visibility) with intelligence (context), both of which are massive big data problems when done right. The founding team has spent more than two decades focused on solving one of the hardest challenges in cybersecurity: massive-scale data ingestion and management.
To that end, Anomali has built a cloud native backend, designed specifically for time series log data, capable of handling petabyte scale ingestion while delivering real-time detection performance.
Core Capabilities
SDPP in the Cloud: Shifting the Burden Away from Customers
Anomali’s approach to SDPP is a key differentiator. Rather than forcing customers to pre-process or normalize data before ingestion, Anomali shifts all security data pipeline operations into its own cloud layer. The result is a frictionless architecture where security telemetry from EDRs, firewalls, identity systems, and cloud sources can be piped in “as-is,” and the parsing, enrichment, filtering, and normalization are all handled automatically in-flight.
This strategy removes the need for agents or edge-based transformation infrastructure, reducing both the complexity and cost typically associated with security data pipelines. The platform supports structured and unstructured log formats, standard syslog inputs, Windows event forwarding, and API-based data sources, allowing enterprises to route their data directly into Anomali’s cloud, where it is automatically enriched and correlated with threat intelligence in real-time.
Underlying Approach
Anomali’s approach to SDPP pipelines diverges from the traditional SDPP model in a few critical ways. Anomali takes a fundamentally different stance: they prioritize ingesting as much raw telemetry as possible upfront, storing it cost-effectively in their cloud-native data lake before any aggressive filtering or transformation is applied. This "ingest-first" model ensures that security teams maintain access to full-fidelity data for retrospective analysis and threat hunting without being constrained by early-stage filtering decisions.
Enrichment is another key differentiator: Anomali’s ThreatStream platform allows for in-line threat intelligence enrichment of logs, meaning data can be automatically matched to IoCs and threat context as it flows into the system. This fits well with Anomali’s DNA. This tightly coupled enrichment pipeline, combined with their built-in SIEM and analytics capabilities, enables real-time detection and long term retention, without the need for separate cold storage tiers. Compared to Cribl’s Lakehouse model, Anomali’s end-to-end platform minimizes the need for intermediary tools, offering both cost savings and architectural simplicity for modern SOC teams.
Converging TIP, SIEM, and Data Lake
Relative to the pure-play SDPP vendors discussed in the report, where Anomali stands out is in its tight integration of threat intelligence and detection analytics. This is a roadmap item for many of the vendors covered. Anomali’s Copilot AI engine further streamlines detection engineering and migration. It can convert SPL and KQL rules from legacy SIEMs into Anomali’s native query language (AQL), significantly reducing the effort required to migrate alert logic, dashboards, and workflows, often completing full transitions in less than a quarter. It also includes an AI front end to AQL, allowing analysts to use spoken English to run complex queries against petabyte-scale datasets and receive results in seconds.
Anomali’s platform unifies the traditional roles of TIPs, SIEMs, and data lakes by offering a single architecture that supports:
IoC correlation and threat matching using enriched feeds
Detection as a service with built-in content libraries and Sigma rule support
Case management and incident response automation
Long term storage and compliance grade log retention
Areas to Watch
While Anomali’s approach to cloud-native SDPP is well-aligned with its broader SIEM and data lake vision, one area to watch closely is how the platform continues to mature its granular SDPP capabilities. Today, Anomali’s strategy emphasizes ingesting data as-is into the cloud for processing, offloading the parsing, normalization, and enrichment to its backend systems. This makes sense for performance and simplicity but as enterprise SOCs deal with increasingly heterogeneous, complex data sources, some customers may eventually seek finer control over transformation logic, custom enrichment pipelines, or in-stream filtering before ingestion. This is where legacy SDPP vendors like Cribl have leaned in, offering advanced rule-based transformations, field extraction logic, and pre-processing layers at scale. However, broadly, they have strong capabilities around their data lake and SIEM capabilities which is an understandable tradeoff.
Analyst Take
Anomali’s evolution illustrates a strong shift that we’re seeing within the landscape in the SIEM and SDPP landscape where vendors merge both capabilities together into a unified platform. By combining its deep TIP heritage with a high-performance data lake architecture and seamless SDPP processing, Anomali is positioning itself as an alternative to both legacy SIEMs and next-gen observability stacks.
Stellar Cyber
Stellar Cyber is an open SecOps platform that offers an integrated, AI-driven and automated approach to threat detection, investigation, and response. Founded in 2015 by Aimei Wei, the company emerged with a vision to simplify and unify security operations through a platform that consolidates traditionally siloed tools, like SIEM, NDR, IT/OT, IDS, UEBA, and SOAR, into a single system sold under one license.
Their open SecOps platform, powered by Open XDR, is focused on providing comprehensive visibility, data transformation, and automated detection across cloud, on-prem, and hybrid environments. The company’s modular data sensors collect telemetry from a broad range of sources, including cloud logs, endpoint agents, and network data, while also integrating third-party tools through a bi-directional API framework.
Stellar Cyber’s Multi-Layer AI™ is their way of packaging “AI” or the intelligence behind its SecOps Platform, delivering machine learning, correlation through GraphML and GenAI capabilities, aimed at improving analyst efficiency by cutting through noise and accelerating threat response. The company is also pioneering Agentic AI, introducing automated triage and intelligent feedback loops designed to continuously adapt and enhance SecOps workflows.
Core Capabilities
Security Data Pipeline & Enrichment Capabilities:
Stellar Cyber’s SDPP architecture is built on modular sensors that operate across diverse data sources, from network traffic and cloud platforms to endpoint logs and existing security tools. These sensors handle critical SDPP stages including parsing, normalization, and enrichment close to the point of ingestion. This design allows for selective filtering and raw log preservation before data is sent downstream, helping to reduce noise and storage costs. Data is centrally processed and enriched with threat intelligence and vulnerability data before landing in a searchable data lake, with additional options for long-term retention in cloud object storage platforms such as Snowflake or S3.
What differentiates Stellar Cyber is how tightly integrated its data processing is with detection and response. While many SDPP focused vendors operate as middleware feeding into SIEMs or observability tools, Stellar Cyber combines the SDPP pipeline with security analytics within a unified platform. Their real-time enrichment and detection capabilities are engineered for both speed and contextual accuracy. The platform supports pre-built detection rules for faster deployment, while still allowing for customization. Use of OpenSearch and Elasticsearch for hot data storage supports scalability and cost efficiency, and long term storage options help balance retention and budget requirements.
XDR & SIEM Augmentation: The platform offers a path for gradual migration away from legacy SIEMs, with tight integrations with Splunk and Microsoft Sentinel. Stellar Cyber positions itself as a complementary platform—particularly for organizations burdened by SIEM complexity. The company offers bi-directional data synchronization and augments SIEM functionality with detection, enrichment, and visualization features. This hybrid model, described internally as a "three-headed monster", combines SIEM, XDR, and SOC automation to reduce reliance on expensive SIEM storage and improve detection accuracy.
Areas To Watch
The platform attempts to cover a broad section of the SOC toolchain, from SIEM to NDR to SOAR. While this consolidation benefits leaner teams, it may not match the depth of best-of-breed vendors in specialized areas like pure-play SDPP. That said, this broad model is intentional. Stellar Cyber is strategically focused on becoming a pane of glass for mid-market and MSSP providers. It resonates strongly with mid-sized IT shops or government agencies with modest budgets and limited staff. Large enterprises with deeply entrenched security programs and specialized stacks may not find the multiple-capabilities model to be an immediate fit without significant customization and integration.
Analyst Take
Stellar Cyber is not a pure-play SDPP pipeline vendor, but rather a fully integrated SOC platform powered by its Open XDR architecture. It brings together NG-SIEM, NDR, IT/OT, IDS, UEBA, and SOAR into a single system.
We were impressed with the modular sensors and third-party integrations. The combination of proprietary sensors and open API options gives customers flexibility in how they ingest telemetry. This hybrid approach allows organizations to preserve existing investments while layering in new capabilities.
A case study involving a large U.S. city highlighted the platform’s value in resource-constrained environments. With limited staff, the city improved visibility, reduced investigation time, and avoided adding headcount, demonstrating clear ROI for mid-market and public sector entities.
Conclusion: The Data Layer Decides
It will be fascinating to watch how this space evolves. Our research shows that purpose‑built Security Data Pipeline Platforms (SDPPs) are no longer optional plumbing; they are the control plane for cost, compliance, and detection efficacy. We believe the Data Layer will yield significant advantages in threat detection, as the data layer becomes foundational to the rest of outcomes within the SOC.
Key points to carry forward:
The capability bar is rising fast. Filtering and schema normalization are table‑stakes; AI‑assisted optimisation and edge‑level enrichment will separate leaders over the next few years.
Data quality is destiny. Every false negative traced in our incident analyses began with missing, malformed, or mis‑routed telemetry.
Pipelines now pay for themselves. Median SIEM‑ingest savings of 40‑65 % shift budget from storage to analytics in the first year.
Execution outpaces vision. Only a handful of vendors combine ARR momentum, open connectors, and a credible roadmap to autonomous data fabrics.
There are many developments in this space as we see new capabilities emerge. We will continue to watch and track how this market evolves over the next few years.
Thank you for reading, and please share this report or your feedback with us.
This is a first of its kind analysis. Excellent job, Francis!
Missing Edge Delta - far superior to most if not all of the products listed.