

From Pipeline to Platform: The Cribl Success Story & the New Frontier of Security Data
An in-depth analysis of Cribl’s rise to becoming a cybersecurity & data platform, how its vendor-neutral architecture eliminated the Splunk data tax and its next moves as a telemetry services cloud.

Actionable Summary
Earlier this year, we wrote about the rise of security data pipelines and the emergence of new companies within this market. Today, we’re doing a deep dive into one of the fastest-growing companies in the data observability and cybersecurity space.
This report zeroes in on the category’s breakout performer: Cribl, a company whose growth curve now invites comparison with Wiz, Snowflake, and Datadog. This report examine the forces that propelled Cribl past 200M in revenue in 6-years, and explain how its vendor-neutral “telemetry services cloud” is redefining enterprise data economics. Overall, we wrap up by tracing the broader shifts happening inside today’s Security Operations Center that make this architecture indispensable and how Cribl has created a new architecture that will affect future SOC teams.

Cribl surpassed $100 million in annual recurring revenue (ARR) in October 2023, becoming the 4th-fastest infrastructure company to attain “centaur” status since its founding in 2018/19. Then, fourteen months later, in January 2025, the company announced that its ARR had doubled to $200 million, while maintaining 70% year-over-year growth. This scale of growth can only be compared with leading cyber companies like Wiz, as we discussed before, or successful infrastructure companies like Datadog that have gone on to become $50B companies.
Cribl’s customer footprint now reaches 50+ of the Fortune 100 and 130 members of the Fortune 500, demonstrating meaningful traction inside the world’s largest enterprises. Over the past twelve months, the company’s overall customer count expanded by more than 50%, while multi-product deployments grew by more than 200% as organizations adopted offerings beyond its flagship product, Stream. That broadening of use cases has pushed their net-dollar-retention above 130% and lifted monthly active users 123% year over year. Cribl Lake, introduced in April 2024, already serves nearly fifty production customers, underscoring the speed at which new modules are being embraced.
Cribl has rapidly established itself as a key player in cybersecurity and data management, positioning itself as the leader based on its scale and depth of customers globally and everything we’ve described above. The company’s impressive growth led to a large funding round in August 2024, where Cribl raised a $319 million oversubscribed Series E round, bringing its valuation to $3.5 billion.
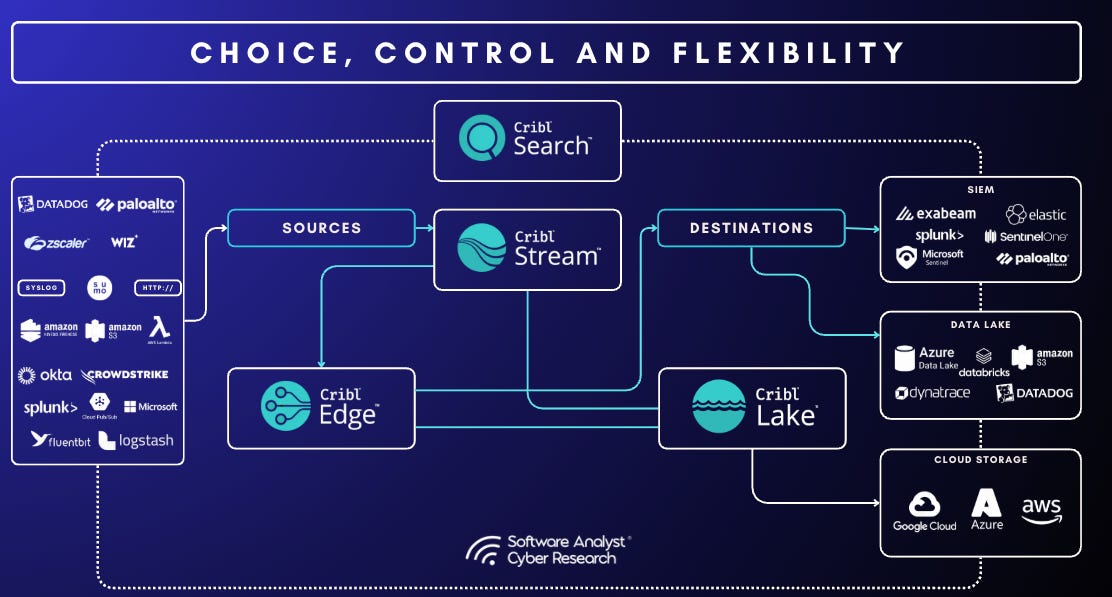
Cribl positions itself as “the Data Engine for IT and Security,” built to give practitioners genuine choice, control, and flexibility over the ever-growing stream of data that is flooding security operations and IT teams. These data sets like logs, metrics, and traces, are generated by their organizations.
Cribl’s product suite, comprising Stream, Edge, Lake, Lakehouse, and Search, addresses critical pain points in data ingestion, collection, storage, and analysis. Cribl’s modular platform works much like an intelligent traffic system:
Cribl Stream trims, enriches, and routes data from any source (e.g. Cloud, network tools) to any destinations (like SIEMs, Data Lake etc).
Cribl Edge applies the same processing right on servers, containers, and devices so only useful data leaves the source.
Cribl Lake and the high-speed Lakehouse keep raw and curated data in cost-tiered object and columnar storage;
Cribl Search lets analysts query that data where it already lives, avoiding re-ingest; and Cribl Copilot is an AI assistant that drafts pipelines, maps schemas, and surfaces anomalies to cut engineering toil.
Together, these services form the company’s emerging “Telemetry Services Cloud,” allowing teams to adopt only what they need today and scale effortlessly as requirements evolve.
Cribl’s success can be attributed to several unconventional moves and a first-mover advantage. The entire security data pipeline industry can be attributed to them as category creators. Key differentiators such as its vendor-agnostic approach, first-mover advantage, and a focus on reducing the data engineering burden for IT and security teams underscore its unique market position. Looking ahead, Cribl’s strategy centers on evolving into a "telemetry services cloud," with continued innovation and strategic partnerships poised to make it a critical infrastructure layer in the cybersecurity and observability landscape.
The Core Insight: How Cribl Broke the Ingest Barrier
Splunk’s breakthrough was bundling log collection, storage, and search into one opinionated stack. A tiny “universal forwarder” (an agent that collects data) sat on every host, streaming raw events to indexers (transforming data into readable/analyzable formats) that transformed data into searchable formats, storing both raw text and fast lookup structures. Analysts used a separate search head layer powered by a schema-on-read engine and SPL (Search Processing Language), enabling them to slice any field on demand. This felt revolutionary compared to rigid relational databases.
The company wrapped this architecture in a pay-by-ingest licence that, in the early on-prem era, offered a clear trade-off: pay a predictable fee per gigabyte, and you could store and search all your logs in one place.. That mix of technical flexibility and simple pricing helped Splunk capture roughly 30% of the SIEM market and made it valuable enough for Cisco to acquire it for $28 billion in 2024. Essentially, they built a walled-garden that charged for every data ingested by them. By selling capacity by the gigabyte ingested, Splunk turned every additional byte into high-margin recurring revenue. Their per-gigabyte licensing and robust content library made it the default choice for enterprises that could afford to index all their logs, yet the same pricing model became a pain point as cloud, remote work and AI increasingly drove the volume of data and telemetry volumes in the enterprise.
Splunk’s Downfall and Cribl’s Rise
Splunk’s ingest-based pricing became its Achilles heel as cloud workloads flooded security teams with terabytes of telemetry. Every byte had to pass through Splunk’s indexers, driving annual license costs into the hundreds of thousands or even millions per terabyte. Many engineers shared tips on trimming data just to stay within budget. A 600 GB-per-day license can easily exceed one million dollars annually.
Cribl shifted the conversation by inserting a neutral processing layer in front of the SIEM. Its Stream pipeline can drop noisy fields, compress verbose logs, enrich events, and then route each record to the most appropriate destination.High-value alerts still go to Splunk, while bulk telemetry lands in cheaper lakes or warehouses. Customers report over 50 percent reductions in Splunk ingest after stripping duplicate lines and low-value fields.
By decoupling ingest from analysis, Cribl turned Splunk from an all-or-nothing destination to just one hop in a flexible telemetry fabric, restoring cost control while preserving the Splunk dashboards that analysts rely on. This led to huge cost savings for security teams as they could flatten their Splunk bills. This vendor agnostic approach gave teams the flexibility to switch/ pivot SIEMs or data lake without rewriting lines of code as they could easily standardize data formats and map logs to OCSF or ECS in less time than the months it took in the past. Many of these factors contributed to their rapid growth.

Company History and Growth Journey
Cribl was officially founded in San Francisco, California in July 2018 by Clint Sharp, Dritan Bitincka, and Ledion Bitincka. All three founders are veterans of Splunk, and their firsthand experience with the limitations of traditional log management (such as high ingestion costs and rigid proprietary formats) inspired Cribl’s mission to "unlock the value of all observability data" without vendor lock-in. Their initial product, originally called LogStream, introduced a "Cribl in the Middle" approach, sitting between data sources and analytic destinations to give users unprecedented control to filter and shape data before it hits expensive storage or SIEM platforms. This paradigm shift allowed customers to send only valuable data to tools like Splunk or Datadog and route less critical data to cheaper storage, solving a major pain point in enterprise security data management.
Cribl's Ascent: A History of Rapid Growth Solving Customer Problems
Cribl’s historic success can be attributed to their ability to solve a pressing problem in enterprise IT and security environments: the explosion of telemetry data, the soaring costs of ingestion, and the lack of flexibility in legacy SIEM architectures. After a number of failed experiments, they finally landed on the idea of Cribl, a data telemetry pipeline that helps security engineering teams. They built a solution between extracted data sources and destinations to give users control to filter and shape data before it hits their storage or SIEM platform. This allowed customers to send only valuable data to tools like Splunk and route less critical data to cheaper storage, solving a major pain point in enterprise security data management.
All three founders, being veterans of Splunk and having experienced firsthand the limitations of traditional log management, inspired Cribl’s mission from day one. Based on our discussions with the founders and early customers, here are a number of key factors that drove a big part of their early successes:
Customer-Centricity & Giving Engineers Control Over Telemetry Chaos
Large enterprises were overwhelmed by fragmented ingestion methods, brittle custom scripts, and slow configuration processes. Admin teams had no direct control over how logs were processed or routed. Cribl focused heavily on the problems faced by these teams.
Cribl Stream gave customers the ability to ingest, enrich, route, and transform data in a modular, controlled fashion, freeing them from reliance on centralized ingestion teams or hard in-house tools. One customer we talked to said:
"It was a management nightmare... custom python scripts weren’t fast enough, so we compiled them in Cython. But no one else could support it if that guy left. With Cribl, it took me 15 minutes. I was like, sign the damn check."
The team was described as "obsessed with solving customer problems related to data flow," demonstrating a commitment to understanding and addressing customer needs. This was central to Cribl's early success, especially since they had some of the largest enterprises as clients. This responsiveness and customer-first approach were indispensable to their initial breakthroughs.
Most legacy ingestion tools lacked fine-grained control. Filtering based on simple rules was easy, but advanced routing, enrichments, and context-aware transformations were painful from data sources like EDR to SIEMs. Cribl enabled customers to build intelligent, rule-based pipelines that operate across diverse data sources, drop irrelevant logs, and insert context early in the pipeline.
Reducing Cost Without Compromising Visibility
The growth of data, especially high-volume log data like VPC flow logs, EDR, and Windows logs, was too expensive to send into Splunk or other SIEMs. Teams had to choose between full visibility and cost. By aggregating and summarizing logs while preserving raw data in cheaper storage like Amazon Security Lake or any solution the customer had, Cribl helped customers slash ingestion volumes by over 90 percent, flattening or reducing SIEM bills.
We spoke to a customer, a large German multinational technology conglomerate, who said:
"We’re ingesting 5 to 7 terabytes daily into Cribl and reducing it to 500 to 600 gigabytes before sending it to Splunk. That’s a 90 to 95 percent reduction in volume. Our ROI analysis showed Cribl could save us millions in Splunk licensing.
Alongside the cost issue was the problem of rigid licensing models, especially in SIEMs, and the lack of flexibility to optimize data storage or pivot between analytics platforms. Cribl introduced a usage-based licensing model with heavy compression, making its Lake and Lakehouse products compelling destinations for low-cost, long-term storage with fast search. One of Cribl’s advantages is its host compression. One customer mentioned: "I was storing four to five terabytes a day for a year, and the price didn’t make sense. It was too cheap. Then I realized it was the compression. That’s what they don’t talk about enough. The host compression is insane."
The Partner First Go-to-Market Strategy
Cribl's highly effective go-to-market strategy was founded on two core tenets: a deep understanding that enterprise software sales are fundamentally a “people business”, and a substantial investment in cultivating robust partnerships. The company prioritized building strong relationships and strategically leveraged the existing market reach of its partners, even offering significant incentives to foster these collaborations. This partner-first approach proved to be an efficient mechanism for “bootstrapping their market engine”, contributing substantially to their rapid growth and market penetration.
Cribl's journey, marked by an initial entrepreneurial setback followed by a decisive pivot and explosive growth, offers valuable lessons in market adaptation. The company's ability to transform an early failure into a foundational strength speaks to an organizational culture characterized by resilience, learning, and a willingness to challenge conventional wisdom.
The “contrarian bet” on a table-based user experience provides a compelling illustration of this. In highly technical and demanding domains like cybersecurity and IT operations, functional scalability, efficiency, and familiarity often hold greater weight than purely aesthetic design choices. Cribl’s growth within key accounts wasn’t incremental, it was exponential. Customers who adopted early kept expanding usage across products and teams. This played a big role in their 100 million dollar growth in the first 18 months and how they unlocked many of the largest enterprises in the world.
The "Contrarian Bet" on User Experience
Security data was siloed. Infrastructure, cloud, and endpoint teams lacked shared visibility and wasted time recreating pipelines or duplicating ingestion work.
Cribl made a deliberate and unconventional choice regarding its user interface (UX), opting for a simple, rule-based table design that cut across siloes and teams. It was a decision rooted in the belief that a table-based interface would offer superior scalability for large enterprises grappling with numerous users and vast quantities of data sources.
Despite initial skepticism from some customers, this familiar interface resonated strongly with IT and security professionals already accustomed to working with similar rule-based tools such as firewalls. This pragmatic approach to UX, prioritizing functional scalability and user familiarity, proved to be a significant enabler of enterprise adoption.
Today, Cribl’s vendor-neutral architecture allows teams across security, infrastructure, and cloud operations to leverage a common pipeline without stepping on each other, reducing duplication and enabling faster incident response. The product has scaled to become one of the most robust solutions for many IT and security teams. It was designed for operational resilience, enabling human oversight, version control, rollback, and repeatable configurations.
The Cribl Data Engine: Core Products and Their Interconnected Evolution
Cribl's product portfolio is a comprehensive suite that comprises four major components:
Stream
Edge
Lake/Lakehouse
Search
These components are designed to work synergistically, providing organizations with unparalleled choice, control, and flexibility in managing telemetry data throughout its entire lifecycle.
Cribl Stream: The Central Nervous System for Telemetry

Cribl Stream is positioned as the “core” component of the data engine. Its fundamental role is to enable users to connect previously unconnected systems, offering exceptional flexibility to move data from virtually any source to any destination, and into any desired tool. This capability is essential for centralizing the management of diverse data sources and destinations within complex enterprise environments.
Stream's primary function is to act as an intelligent intermediary, allowing organizations to process, filter, and reshape telemetry data before it reaches its final destination. It acts as a centralized “traffic cop” for telemetry data, collecting, shaping, and distributing events in real time, all with high scalability and fine-grained control. Cribl Stream can handle anything from megabytes to petabytes of data per day, scaling horizontally to meet enterprise volumes. For instance, a five-terabyte data source can be efficiently reduced to three terabytes by filtering out irrelevant information, optimizing storage and processing costs downstream.
This decoupling of data producers from consumers is a critical architectural advantage, as it insulates organizations from the rigidities of vendor lock-in and empowers them to optimize data specifically for the unique requirements of different consuming systems or applications.
Cribl Stream can ingest telemetry from virtually any source, supporting over 80 out-of-the-box integrations for data inputs and outputs. Engineers can replay and reuse data. An important feature is Cribl Stream’s “Replay” capability, especially in conjunction with Cribl Lake. Stream can intentionally send a copy of all raw data to low-cost storage like S3 or Cribl Lake and keep only filtered data in expensive tools. Later, if needed, users can replay data from that archive back through Stream to a tool for deeper analysis.
Future iterations:
Co-pilot Editor: A pivotal enhancement is Copilot Editor launched June 4, 2025. It introduces an AI-powered, intent-aware editor that translates raw logs into standard schemas (like OCSF), builds pipelines, and suggests data filters, all with full human-in-the-loop oversight to prevent errors and preserve visibility. The goal is to help IT and security teams more easily map schemas, translating logs across disparate systems into industry-standard formats with pipelines of sequences that process and transform data to the right destination.
New Kubernetes optimizations include Helm chart support and CPU limit auto‑alignment for Stream and Edge deployments. These improvements, along with multi‑destination routing, inline enrichments, and field‑level filtering, reinforce Stream’s advanced functionality allowing including some of their largest customers to remove unwanted telemetry with precision and strong performance.
In summary, Stream was their first product and remains core to their success. It generates the highest revenue, and most customers start their journey here.
Cribl Edge: Data Collection at the Source
Cribl Edge is a lightweight agent that extends Cribl’s processing to the edge of the network (e.g. servers, cloud VMs, containers, and endpoints) for data collection, especially in environments where comprehensive solutions may be lacking. Edge enables the collection of telemetry data in open formats directly at the point of emission, which helps offload collection and processing workloads from central systems to the edge. This distributed model improves overall efficiency and reduces the burden on core infrastructure. It is particularly useful for high-volume use cases like endpoint monitoring or IoT, where volumes are high and processing some data locally with Edge can significantly improve performance..
Some notable capabilities of Cribl Edge include:
Scalability: Edge supports managing up to 250,000 Edge nodes from a single central leader, making it suitable for large-scale endpoint data collection across diverse environments.
Kubernetes Support: For Edge agents deployed in Kubernetes environments, the platform offers full visibility into namespaces, pods, and services. This simplifies administration in containerized infrastructures.
Offline Data Handling: Edge is designed to accommodate intermittently connected devices, such as laptops that frequently go offline. It adjusts for time delays in event data and helps maintain integrity even with unstable connectivity.
Cribl Lake & Lakehouse: Flexible Storage and Tiered Data Management
Cribl Lake
Cribl Lake is a turnkey data lake for telemetry data that emphasizes cost-effective storage and easy retrieval. The idea behind Lake is to give organizations a scalable, schema-less repository for storing “cold” data (logs and metrics that aren’t needed for immediate analysis but must be retained for compliance or future investigations).
Traditional data lakes or warehouses struggle with the unpredictable, semi-structured nature of log data. They require rigid schemas and heavy ETL processes to make the data usable. Cribl Lake, by contrast, automatically optimizes and indexes any incoming data in an efficient format, without requiring users to define schemas upfront.
It is tightly integrated with Cribl Search, so teams can instantly search data in the lake without moving it elsewhere. In essence, Cribl Lake acts as an “open” alternative to vendor-specific log archives: companies can retain full-fidelity data for as long as needed at a fraction of the cost of keeping it in Splunk or Datadog, and still query it on demand. As one customer mentioned, the host compression is very good. A financial customer we spoke to emphasized the strategic value of Cribl Lake in enabling selective routing: only high-value logs are forwarded to Splunk, while the bulk, like proxy and DNS data, is stored in Lake for long-term retention. With compression ratios of 80 to 85 percent, customers store petabytes of data at cost structures far below ingestion-based platforms. Lake also integrates tightly with existing S3-compatible object stores, supports on-demand provisioning, and allows metadata-enriched rehydration, meaning old logs can be queried or reprocessed later if new threat indicators emerge.
Cribl Lakehouse
In early 2025, Cribl announced Cribl Lakehouse, an evolution of this product that blends the best of data lakes and data warehouses for telemetry data. Cribl Lakehouse is a faster, query-optimized analytics layer that sits atop Cribl Lake. It is like a columnar, low-latency data warehouse for hot or warm log data. It enables interactive querying of recent telemetry at millisecond speeds, with full RBAC and dynamic provisioning.
Lakehouse architecture eliminates manual data prep and delivers real-time query capabilities on top of the Cribl Lake, all managed through a unified interface. This allows IT and security teams to operate “many lakes as one,” scaling across regions and tiers of storage while cutting storage costs by ~50% compared to traditional solutions.
Cribl Lakehouse functions as a columnar store, optimized for millisecond-level access to high-priority data, making it ideal for real-time analytics and critical security operations. Cribl Lake provides snappier access for data designated for long-term retention, balancing accessibility with cost-efficiency. The original Cribl Search component continues to serve as a solution for purely archival data needs. This multi-tiered approach empowers organizations to balance cost and value by storing data according to its importance, criticality, and the required query speed.
Cribl Lake simplifies the complexities of data storage by offering a straightforward, cost-effective solution for data whose future value or immediate utility might be uncertain. It automates the often-cumbersome processes of commissioning, partitioning, and role-based access control with a "one-click" setup, abstracting away the underlying complexities of managing object storage. This is particularly beneficial for managing PII through different data versions, ensuring compliance and data privacy. Furthermore, Lakehouse robustly supports hybrid deployment environments, encompassing both on-premise and cloud infrastructures, which is vital for organizations with diverse data sovereignty requirements and localization needs.
Overall, it's notable what Cribl has achieved in this architecture. This can now help accelerate incident response, forensic investigations, and compliance reporting, as security teams can query extensive historical datasets without the time delays and prohibitive costs associated with data rehydration or maintaining redundant, expensive storage systems. The "bring your own bucket" feature further enhances data sovereignty and reduces third-party risk, as the data remains entirely within the customer's infrastructure, addressing critical enterprise concerns that extend far beyond just performance optimization.
Cribl Search: Federated Analytics and Unified Data Access
Cribl Search is a federated analytics and search-in-place engine designed to allow users to seamlessly connect and access diverse datasets regardless of whether it is in their own SIEMs, object storage, Cribl Lake, or at the Edge. Customers can run queries without requiring indexing or upfront ingestion. It functions as an analytical query engine for unstructured data.
This eliminates cases where analysts must navigate multiple disparate tools to access different data sets. Based on a Cribl customer we spoke to, Search enables new use cases by decoupling ingestion from analysis. They route only critical logs to Splunk for active security workflows, while storing bulk logs (like proxy, DNS, and VPC flow) in Cribl Lake. When necessary, analysts can use Cribl Search to query the Lake without needing ingestion or extra compute resources.
The integration with Discover Intelligence, a third-party connector, enables hybrid querying, additionally giving users the ability to trigger Cribl Search queries from Splunk dashboards. Cribl's usage-based pricing model, combined with host-based compression, allows storage of multi-terabyte daily log volumes for a fraction of the cost of traditional systems.
Cribl Search continues to undergo significant enhancements:
New improvements include real-time fast query across indexed and non-indexed datasets, regional query acceleration, and support for BYO authentication and storage models, extending Search into enterprise-grade data lake environments.
Search Packs: The platform has rolled out support for "search packs," which provide a framework for streaming content. These packs offer pre-configured content, including dashboards and the necessary configurations, to rapidly enable specific use cases. For example, if a new data source from a partnership is integrated, search packs can provide out-of-the-box dashboards for immediate data visualization and analysis.
Dashboard Scheduling: A critical feature for accelerating analysis is dashboard scheduling. Rather than accelerating individual searches, users can now schedule entire dashboards to be pre-cached at regular intervals.
AI-powered Co-pilot
Cribl has integrated an AI-powered Co-pilot, an interactive tool designed to assist users in building pipelines more efficiently and changing data schemas between sources and destinations. These tools automate schema mapping, pipeline building, source onboarding, and log enrichment, dramatically reducing time to value. Copilot Editor understands log structure and semantics, suggests functions, validates transformations, and lets teams retain full control with a human-in-the-loop model. Customers benefit from this AI-assistive model, allowing non-experts to process complex logs (such as OCSF or ECS schemas) without needing deep ETL experience. Copilot accelerates onboarding for new cloud services and ensures clean, enriched data reaches downstream tools, improving fidelity, reducing false positives, and accelerating incident response. It helps to offload the complex and time-consuming work of building parsers and mappers. Copilot Editor is embedded across Stream, Search, and Edge.
Cribl's Future: Unpacking the Success Factors
Cribl's rapid ascent and prominent market leadership are firmly rooted in several strategic differentiators that directly address fundamental pain points prevalent in enterprise telemetry data management.
Empowering Customer Choice, Control, and Flexibility
A consistent and overarching theme in Cribl's philosophy is the empowerment of customers with choice, control, and flexibility. The company operates on the principle that organizations should be able to embrace new technological choices while seamlessly integrating and leveraging their existing investments. The adage that "nothing in the Enterprise ever goes away" is a guiding tenet, underscoring the necessity for solutions that can integrate with legacy systems while simultaneously enabling modernization.
Partnerships To Accelerate SIEM Migrations
Cribl has deeply integrated its Stream platform with both CrowdStrike Falcon Next‑Gen SIEM and Palo Alto Networks Cortex XSIAM, enabling organizations to migrate from legacy SIEMs faster, more securely, and cost‑efficiently. Through the Technology Alliance Partner (TAP) program, Cribl and CrowdStrike launched the CrowdStrike Falcon Next Gen SIEM destination and jointly developed CrowdStream, a native data routing capability within Falcon. This simplifies ingestion of any source telemetry directly into the Falcon ecosystem, eliminates manually intensive configuration, and reduces ingestion costs while preserving full event context.
Similarly, in April 2025 Cribl and Palo Alto Networks rolled out a co‑developed Cortex XSIAM destination and source integration within Cribl Stream. This partnership empowers SOC teams to centrally collect, enrich, and route high-quality data into XSIAM, accelerating proof of concepts, safeguarding historical data, and enabling legacy to XSIAM migration without blind spots. By offloading ingestion logic, normalizing fields, and maintaining fidelity with configurable backpressure and persistent queues, Cribl minimizes downtime, cutovers, and cost overruns. This fuels faster adoption of AI driven SIEMs like Falcon NG SIEM and Cortex XSIAM.
Real-World Impact: Customer Case Studies
We got to hear from a large and prominent Canadian financial institution that undertook a significant SIEM migration from an on-premise QRadar deployment to Splunk Cloud. Leveraging Cribl, this bank completed the complex migration in a remarkably efficient nine months, a stark contrast to the approximately one year it took for previous migrations. Cribl simplified the entire process by managing data ingestion and indexing, alleviating the need for extensive coordination with SIEM experts. This flexibility allowed them to execute the migration at their own pace.
The institution specifically chose Cribl over a Kafka-based solution due to Cribl's ease of use and greater flexibility, avoiding the necessity of deploying “an army of Java developers”. Furthermore, Cribl enabled them to route the same data to multiple destinations, serving disparate teams and purposes without incurring the prohibitive costs associated with sending all data through the high-cost SIEM. This capability also enhanced data isolation by directing data to specific tools for specific teams, preventing unnecessary access to the core SIEM and bolstering overall data governance.
Cribl's Philosophy on Co-existence and Ecosystem Enablement

Cribl's core philosophy dictates that the data processing engine should be architecturally separate from the security solution itself. This separation empowers partners to concentrate on building and selling their specialized solutions on top of Cribl's platform, which Cribl aims to make the best in class for processing telemetry data. This approach fosters a rich ecosystem of solutions, where various vendors can build specialized security, observability, or other applications. A fundamental tenet is customer choice, ensuring that organizations can select their preferred tools, with Cribl facilitating data accessibility to any solution built on its platform.
Cribl, having originated as a data pipeline company and expanded into storage and search, is moving towards a comprehensive telemetry data management platform. Its expertise lies in handling the unique requirements of telemetry data, which often pose challenges for general-purpose data processing solutions. While Cribl remains open to developing solutions where market gaps exist, it generally has less appetite for entering “red ocean” spaces, such as the crowded SIEM market, where numerous strong competitors already exist. Instead, its primary focus remains on the underlying data processing engine, preferring to enable rather than directly compete with established application-level vendors.
Vendor-Agnostic Approach / No SIEM
Cribl deliberately refrains from being categorized as a Security Information and Event Management (SIEM) solution. Instead, it emphasizes its vendor-agnostic approach and its core focus on comprehensive data management. This strategic positioning allows Cribl to supplement existing security and IT solutions rather than necessitating their costly and disruptive replacement. This approach provides organizations with substantial flexibility and helps them avoid the high costs and inherent risks associated with full-scale migrations.
By operating as a vendor-neutral layer, Cribl effectively insulates its customers from market disruptions, such as acquisitions or mergers among their existing vendors, thereby empowering them with greater choice and control over their data infrastructure.
The decision by Cribl to avoid the "SIEM" label and to position itself as vendor-agnostic represents a sophisticated market strategy that directly capitalizes on widespread dissatisfaction with the escalating costs and vendor lock-in associated with traditional SIEM platforms. Enterprises frequently express "perennial disappointment" with the cost-effectiveness of their SIEM solutions and are "always looking for options" to mitigate these challenges. Full-scale SIEM migrations are notoriously "expensive" and "risky," often taking a year or more to complete, involving significant operational disruption and the porting of complex alerts and rules. Cribl's vendor-agnostic stance directly addresses this dilemma by offering a flexible layer that allows organizations to optimize and route data to their existing SIEMs, or even new ones, without requiring a complete rip and replace.
This enables organizations to experiment with new tools, implement robust data tiering strategies, and manage costs more effectively, all while preserving their current investments. By establishing itself as an indispensable data utility that underpins and powers all security and observability tools, Cribl carves out a unique and defensible market position. This position transcends direct competition with application-level vendors, instead making Cribl an essential component of the modern enterprise data fabric.
The Future: Telemetry Services Cloud As An Infrastructure
Cribl’s long-term vision is centered around building a "Telemetry Services Cloud", a programmable, composable data platform that abstracts away the operational burden of handling massive telemetry volumes while giving users full control over how their data is collected, processed, stored, and searched. This direction reflects a fundamental belief that data growth is outpacing enterprise budgets, and that organizations need a more flexible alternative to centralized systems like traditional SIEMs and rigid observability stacks.
At its core, Cribl is rearchitecting the data pipeline by decomposing it into modular primitives: collection (Edge), processing and routing (Stream), storage (Lake and Lakehouse), and analysis (Search). These components can be adopted independently or as a cohesive platform. The key insight is that users should not be forced into one-size-fits-all infrastructure. Instead, Cribl wants to give users composable building blocks to create cost-effective pipelines tailored to their specific needs.
In parallel, Cribl has made a deliberate decision not to be a traditional SIEM replacement. While some customers note that Cribl could plausibly serve as the foundation for a next-generation SIEM, citing its flexible search, tiered storage, and elastic licensing, it is important to note that it lacks the mature content, threat intel integrations, and advanced analytics of incumbents like Splunk. Neither does Cribl have interest in moving toward that market.
Cribl’s ambition is instead to sit beneath those platforms, enabling faster, cheaper, and more efficient data preparation for security and observability tools alike.

Security Operations (SecOps) Teams
Security operations teams can use Cribl to gain control over telemetry before it reaches detection and response systems. Cribl Stream allows security engineers to shape data from multiple sources such as EDR platforms, firewall logs, and identity systems. This includes filtering low-value events, adding enrichment like asset classification or geolocation, and transforming records into a normalized schema.
The platform can be used to preprocess data to reduce alert fatigue and streamline downstream correlation. In several customer environments, Cribl is deployed to ingest more diverse data into SIEM platforms, enforce routing based on team access, reduce data volumes, and provide transformation logic that aligns with detection rules. The ability to control what enters the detection pipeline supports better triage, lowers total cost of ingestion, and introduces a policy-driven model for data governance. Cribl's role is not to detect threats directly but to enable consistent, high-quality data inputs for the systems that do.
IT Operations Teams
IT operations teams interact with telemetry at scale across networking, infrastructure, and application layers. Cribl can serve as a telemetry normalization and routing engine that allows these teams to direct operational logs to relevant destinations based on service tiers, time windows, or region. It reduces dependency on brittle forwarding logic or multiple agents by centralizing control. For example, logs from Linux systems can be filtered to remove routine events, enriched with tags such as environment or owner, and routed to different storage classes or observability tools.
The system can also be used to decouple ingestion from immediate analysis, which gives teams the option to store logs in Cribl Lake and retrieve them later for investigation through Cribl Search. This supports a tiered logging strategy where high-priority signals are streamed in real time, while long-tail data is stored for audit, forensics, or compliance purposes.
Cloud and Platform Engineering Teams
Platform engineering teams are responsible for maintaining telemetry pipelines across multiple environments including cloud providers, on-premise systems, and container orchestration platforms. Cribl can provide mechanisms to aggregate and normalize data from sources like AWS CloudTrail, Azure Monitor, and Kubernetes audit logs. Edge nodes can be deployed close to the source, minimizing latency and egress costs, while Cribl Stream provides schema transformation to align data with industry standards such as OCSF.
This standardization simplifies routing to cloud storage, monitoring platforms, or cost allocation dashboards. Some teams use Cribl to assign metadata for chargeback purposes or to ensure telemetry conforms to enterprise compliance policies before forwarding to downstream analytics. The flexibility of deployment options, including cloud-hosted control planes and on-premise workers, allows platform teams to scale their telemetry layer independently of application or network changes. The outcome is a structured approach to telemetry flow that can be adapted as infrastructure expands or shifts across environments.
Observability and SRE Teams
Observability and site reliability engineering teams are responsible for tracking the performance and availability of applications and services. Cribl can assist these teams in managing the volume and complexity of telemetry by providing filtering, enrichment, and transformation at ingestion time. This includes reducing cardinality in metrics, discarding redundant traces, and correlating logs with deployment metadata. Cribl’s integration with tracing and metrics sources enables observability teams to enforce policies such as dropping verbose debug traces during stable periods or dynamically sampling based on system load.
Cribl Search extends this capability by allowing engineers to run queries directly on stored data without rehydrating it into an analytics engine, which is useful for incident response or historical debugging. The platform also supports replaying past telemetry into new tools, which facilitates validation of new detection rules or performance baselines. Cribl can function as a data control layer that enables more precise use of observability tools without requiring lock-in to specific vendor pipelines.
Overall, we can say that Cribl’s utility as a data infrastructure layer spans multiple operational teams. Rather than centralizing around a single use case or toolset, it introduces a flexible control point for routing, shaping, and retrieving telemetry across the lifecycle. The platform supports policies that enforce data quality, optimize resource use, and enable downstream systems to perform more effectively by operating on structured, relevant inputs. Each team leverages this infrastructure to meet different functional requirements but benefits from a shared abstraction layer that improves interoperability and scale.
Cribl is also making strategic investments in performance, developer experience, and AI. Their Copilot Editor applies intent-aware AI to simplify pipeline creation, schema matching, and field enrichment, while preserving human-in-the-loop validation. Innovations like streaming enrichment, direct object store ingestion (for example, from S3), and Federated Search provide a foundation for more headless, scalable, and distributed SOC architectures. The product roadmap is already addressing real customer pain points such as GitOps workflows, metrics pipelines, and workspace isolation, signaling a focus on building durable infrastructure rather than hype-driven features.
In conclusion, one of our biggest findings was that Cribl's future is not about competing with SIEMs. Instead, their aim is to provide the backbone telemetry fabric that existing SIEMs, XDRs, and AI tools plug into. It is about freeing enterprises from rigid data dependencies. By rethinking how telemetry data is onboarded, enriched, routed, and analyzed, Cribl is laying the foundation for a telemetry-native cloud infrastructure, purpose-built for the performance, scale, and flexibility demands of modern security and observability teams. As the volume and complexity of data continue to grow, Cribl is positioning itself to be the infrastructure layer that helps teams keep up.

Where the SOC Is Heading and Why the Pipeline Sits at the Center
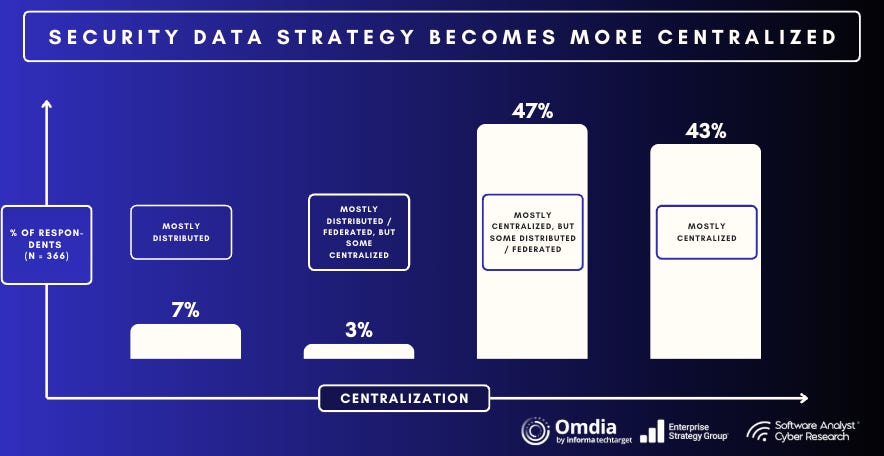
Tomorrow’s security stack will invert the SIEM model we inherited from the Splunk era. Instead of marching every byte into a proprietary store and paying to search it later, teams are keeping full-fidelity telemetry in an open security data lake (Snowflake, Databricks, S3, BigQuery, etc.) and sending only security-relevant data to the SIEM for real-time correlation. Analytics engines now “come to the data,” running detections inside the lake rather than extracting it. This shift restores data ownership, slashes storage tax, and lets specialist tools plug in without another round of mass re-ingest.
To make that architecture work, organisations first need an independent streaming pipeline that can collect at the edge, normalise to open schemas like OCSF/OTel, enrich with threat-intel and identity context, and route each record to the right target like a SIEM, lake, SOAR, or archive in real time. Pipeline platforms such as Cribl’s Stream and Edge already provide that connective tissue: Reddit’s engineers, for example, used a Cribl layer to dual-write events to Splunk and a new Kafka + BigQuery stack, validating the lake-native system before they turned off Splunk, all with a routing-rule change and no impact on sources.
Once the data flows are clean and portable, the SOC can layer on truly lake-native analytics. Columnar query engines (e.g., those that speak Kusto Query Language) scan petabytes in seconds; AI-driven assistants now translate plain-English hypotheses into optimised KQL hunts, allowing analysts to pivot without memorising syntax. Because detections and investigations execute where the telemetry already resides, response time improves while costs stay tied to low-price cloud compute rather than high-price SIEM ingestion.
In short, the future SOC looks decentralized, lake-centric, and pipeline-defined. The SIEM remains vital for high-fidelity correlation, but its radius shrinks. The data lake becomes the system of record, and a vendor-agnostic pipeline, embodied today by Cribl and its peers, emerges as the strategic control plane that keeps telemetry trustworthy, affordable, and ready for whatever analytics engines come next.
****
Thank you for reading. If you haven’t read our security data pipeline report, please read everything above.
***
Great analysis on Cribl!
Well done. I like the customer examples. Do you have more examples of executive level metrics that justify an investment in an independent pre-processing layer? Outside of "reducing by SPLK bill". Early adoption was driven by "reducing my SIEM bill" but, IMO, long term growth will be supported by strategic and business level support. Otherwise, the next gen "system of analysis" collection and pipeline tool could be "good enough". Thoughts?